As the field of machine learning continues to grow, new techniques and algorithms are constantly being developed to improve its capabilities. One such technique is linear classification, which is a fundamental concept in machine learning. Linear classification involves the process of classifying data into different categories based on a linear decision boundary.
In simpler terms, linear classification is a way of separating data into different groups by drawing a straight line or hyperplane that divides the data. This technique is commonly used in a variety of applications, such as image recognition, speech recognition, and natural language processing. It is also an important building block for more complex machine learning models, such as neural networks. Understanding the basics of linear classification is essential for anyone looking to develop machine learning models that can accurately classify data.

What is Linear Classification in Machine Learning?
Linear Classification in Machine Learning is a method of classifying data points into two or more categories by using a linear hyperplane. This is done by finding the optimal separating hyperplane that best divides the data points into their respective classes. The hyperplane is chosen based on the data points’ features, coefficients, and weights which are then used to classify the data points.
Data Representation
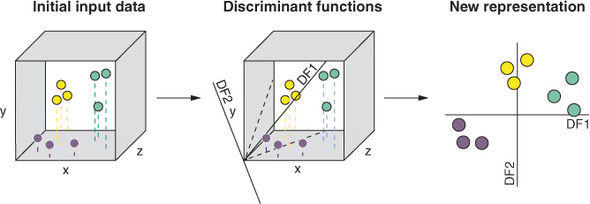
In order to use linear classification, the data must first be represented in a way that can be processed by the algorithm. This representation is done by assigning values to each feature of the data. For example, for a data point containing two features (x1 and x2), each feature can be assigned a numerical value such as x1= 2 and x2= 4. The numerical values are then used to build a hyperplane which is used to separate the data points into their respective classes.
Hyperplane
The hyperplane is used to separate the data points into their respective classes. It is defined by a set of coefficients, weights, and features that are chosen based on the data points. The hyperplane is then used to classify the data points by calculating the distance of the data point from the hyperplane. If the distance is greater than a certain threshold, the data point is classified as belonging to one class, and if it is less than the threshold, it is classified as belonging to another class.
Training and Testing
Once the data is represented and the hyperplane is defined, the algorithm can then be trained and tested. The training phase involves optimizing the hyperplane parameters to achieve the best possible accuracy. This is done by using an optimization algorithm, such as gradient descent, which is used to find the best set of parameters that maximize the accuracy of the model. The testing phase involves evaluating the accuracy of the model by using a test data set.
Applications
Linear Classification in Machine Learning can be used for a variety of applications such as image recognition and spam filtering. In image recognition, the algorithm can be used to classify images into different categories. In spam filtering, the algorithm can be used to classify emails into spam or non-spam categories.
Advantages
Linear Classification in Machine Learning has several advantages. One of the main advantages is that it is simple to understand and implement. Additionally, it is fairly efficient and can be used to classify data points quickly. Finally, it is also flexible, as it can be used for a variety of applications.
Disadvantages
Linear Classification in Machine Learning also has some drawbacks. One of the main drawbacks is that it can only be used to classify data points into two categories. Additionally, the algorithm can be prone to overfitting, which can lead to inaccurate results. Finally, the algorithm is also limited in its ability to capture non-linear patterns in the data.
Frequently Asked Questions (FAQs)
Linear classification is a supervised machine learning technique used to assign a label to a given input data. It can be used for a variety of tasks, from predicting a customer’s likelihood to buy a product to predicting whether a patient has a certain disease.
What is linear classification in machine learning?
Linear classification is a supervised machine learning technique used to assign a label to a given input data. It is based on the idea that there is a linear relationship between the input data and the output label. This means that the output label can be predicted based on the input data by using a linear equation. For example, if the input data are features about a customer such as age, gender, and income, then the output label may be a prediction of whether or not the customer is likely to buy a certain product.
The linear classification algorithm works by finding the linear equation that best fits the given input data. The equation is then used to make predictions about the output labels. The algorithm uses a loss function to measure how well the equation fits the data and continues to refine the equation until it finds the best fit. Once the best fit is found, the equation can be used to make predictions based on new input data.
How is linear classification used?
Linear classification is used for a variety of tasks in machine learning. It can be used to solve classification problems such as predicting whether a customer is likely to buy a product or not, or to predict whether a patient has a certain disease or not. It can also be used to solve regression problems such as predicting a customer’s age or income. Linear classification can also be used for a variety of other tasks such as feature selection and anomaly detection.
Linear classification is often used in combination with other machine learning techniques such as neural networks and support vector machines. This allows the linear classifier to be used to pre-process the data, such as feature selection and normalization, before it is passed to the other machine learning techniques for further processing. This allows the other techniques to work more efficiently and often produces better results.
What are the advantages of linear classification?
One of the main advantages of linear classification is that it is relatively simple to implement and understand. It is also fast and efficient, making it suitable for large datasets. Additionally, linear classification can be used to make predictions with high accuracy.
Another advantage of linear classification is that it can be used to reduce the dimensionality of data. By finding the linear equation that best fits the data, the linear classifier can reduce the number of features in the data, making it easier to work with. This can improve the accuracy of the predictions, as well as reduce the time and computational cost of training and using the model.
What are the disadvantages of linear classification?
One of the main disadvantages of linear classification is that it is only suitable for linear problems. If the data is non-linear, then linear classification may not be able to accurately predict the output labels. Additionally, linear classification may not be able to capture complex relationships between the input data and the output labels.
Another disadvantage of linear classification is that it can be sensitive to outliers in the data. If the data contains outliers, then the linear equation may be influenced by them and may not accurately predict the output labels. Additionally, the linear equation may not be able to capture more complex relationships between the input data and the output labels.
What are some alternatives to linear classification?
Some alternatives to linear classification include support vector machines, neural networks, and decision trees. These techniques are more powerful than linear classification and can be used to solve both linear and non-linear problems. Additionally, they can often capture more complex relationships between the input data and output labels.
These techniques are more computationally intensive than linear classification, so they may not be suitable for large datasets. However, they can often produce more accurate predictions than linear classification, so they may be worth the increased computational cost.
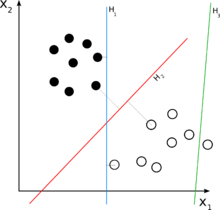
In conclusion, linear classification is a fundamental concept in machine learning that forms the basis for many advanced algorithms. It involves separating data points into different classes by drawing a linear boundary between them. Linear classification is widely used in a range of applications, including image classification, sentiment analysis, and natural language processing. By understanding the principles of linear classification, machine learning practitioners can build more accurate and efficient models that can make predictions with high accuracy.
As the field of machine learning continues to grow and evolve, it is important to have a solid understanding of linear classification. The ability to classify data accurately is a critical component of many real-world applications, and linear classification is an essential tool for achieving this goal. Whether you are a seasoned machine learning professional or just starting out in the field, understanding the principles of linear classification can help you build better models and make more accurate predictions. With the right tools and techniques, you can leverage the power of linear classification to unlock new insights and drive innovation in a wide range of industries.