Data leakage is a critical issue that can cause severe damage to any organization. In today’s digital world, companies store and process vast amounts of data, and it is essential to ensure that this data is not leaked or compromised. With the emergence of machine learning, data protection has become even more challenging. However, there are several methods that organizations can employ to prevent data leakage in machine learning.
Machine learning is an excellent tool for organizations to gain insights and make informed decisions. However, it is vital to ensure that the data used for machine learning is appropriately protected. Data leakage can occur in various ways, such as through insider threats, accidental disclosures, or cyber-attacks. In this article, we will explore various methods that organizations can use to prevent data leakage in machine learning, including data masking, access control, and encryption.
Preventing Data Leakage with Machine Learning
Data leakage is a major concern for businesses, especially when it comes to machine learning. Here are some tips for ensuring data leakage is prevented when using machine learning:
- Ensure your data is secure and encrypted.
- Implement a strong data governance policy.
- Set up user authentication protocols.
- Audit and monitor data access.
- Train employees to recognize potential data leakage risks.
By following the tips above, businesses can be sure that their data is secure and protected from leakage when using machine learning.
How to Prevent Data Leakage in Machine Learning
Data leakage is a common issue associated with machine learning. It occurs when a machine learning model is exposed to data outside of its training set, resulting in inaccurate predictions and wrong conclusions. This article will provide an overview of how to prevent data leakage in machine learning and will discuss the steps necessary to ensure that data leakage does not occur.
Understand the Data Leakage Process
Before you can begin to prevent data leakage, it is important to understand the process behind it. Data leakage occurs when a machine learning model is exposed to data that was not used in the training set. This can happen in a variety of ways, such as when a machine learning model is exposed to data from a different time period than the training set. In other cases, data leakage can occur when a machine learning model is exposed to data from a different source or different environment than the training set.
Data leakage can also occur when a machine learning model is exposed to data that is not representative of the data that it was trained on. For example, if a machine learning model was trained on data from a single city, but then is exposed to data from a different city, it may not be able to accurately make predictions on the new data. It is important to understand the data leakage process in order to prevent it.
Check Your Data Sources
The first step in preventing data leakage is to check your data sources. It is important to make sure that all of the data that is being used in the machine learning model is coming from the same source and is representative of the data that was used in the training set. For example, if the training set was created using data from one city, then all of the data used in the machine learning model should also come from that same city.
It is also important to make sure that the data being used in the machine learning model is up to date. If the data is from a different period than the training set, it may not be representative of the data that the machine learning model was trained on and could lead to data leakage. It is important to check the data sources regularly to ensure that the data being used is up to date and representative of the data that the machine learning model was trained on.
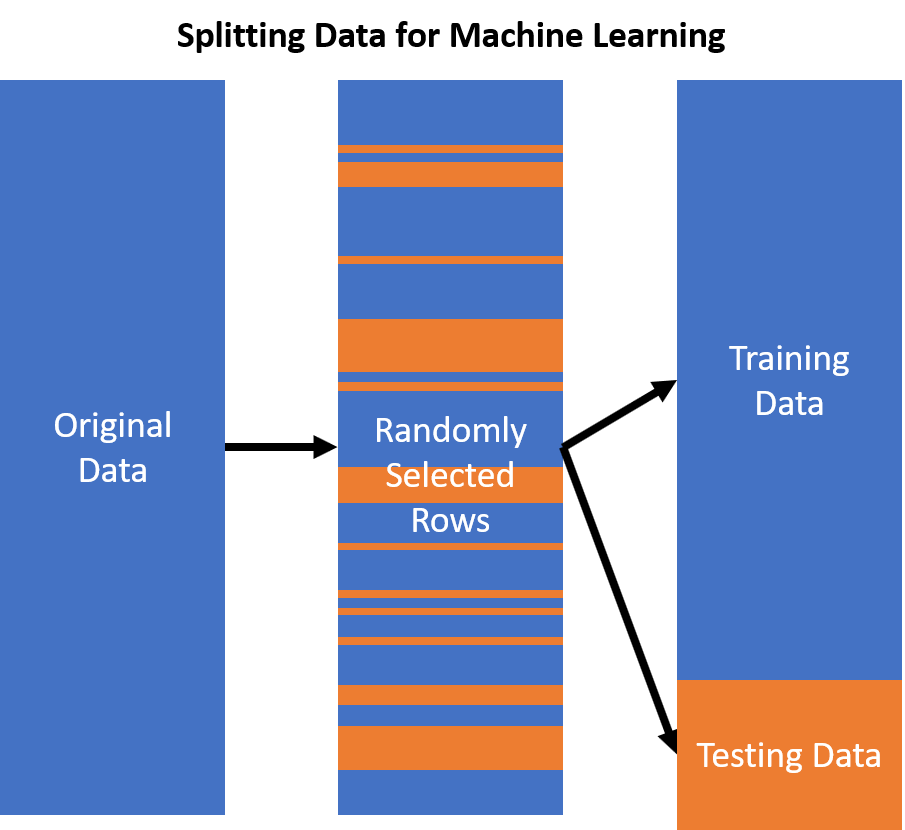
Split Your Data Sets
One way to prevent data leakage is to split your data sets into training, validation, and testing sets. By doing this, you can ensure that the machine learning model is not exposed to data outside of its training set. It is important to keep the training set separate from the validation and testing sets, as this will help prevent the machine learning model from being exposed to data outside of its training set.
It is also important to make sure that the data sets are split in a way that is representative of the data that the machine learning model was trained on. For example, if the training set was created using data from one city, then the validation and testing sets should also be split in a way that is representative of the data from that city.
Use Data Augmentation
Data augmentation is a technique used to increase the amount of data available for training a machine learning model. By augmenting the data, you can ensure that the machine learning model is exposed to more data and is able to make more accurate predictions. Data augmentation can also help to reduce the risk of data leakage, as it can ensure that the machine learning model is exposed to more data and is not exposed to data outside of its training set.
Data augmentation can also help to reduce the risk of overfitting. Overfitting occurs when a machine learning model is too closely tied to the data that it was trained on, and does not generalize well to new data. By augmenting the data, you can ensure that the machine learning model is exposed to more data and can generalize better to new data.
Use Regularization Techniques
Regularization techniques are used to reduce the complexity of a machine learning model and prevent it from overfitting. Regularization techniques can help to reduce the risk of data leakage, as they can ensure that the machine learning model is not exposed to data outside of its training set. Examples of regularization techniques include l1 and l2 regularization, dropout, and early stopping.
Regularization techniques can also help to improve the accuracy and performance of the machine learning model. By using regularization techniques, you can ensure that the machine learning model is not overfitting and is able to generalize better to new data. This can help to reduce the risk of data leakage and ensure that the machine learning model is making accurate predictions.
Monitor and Test Your Model
It is important to monitor and test your machine learning model regularly. Monitoring the performance of your machine learning model can help to identify any potential issues or data leakage before it occurs. Regular testing of the machine learning model can also help to ensure that it is making accurate predictions and is not being exposed to data outside of its training set.
It is also important to audit your machine learning model regularly. Auditing your machine learning model can help to identify any potential issues or data leakage that may be occurring. Auditing can also help to ensure that the machine learning model is making accurate predictions and is not being exposed to data outside of its training set.
Frequently Asked Questions:
Data leakage is a growing concern in the field of machine learning. This article provides insights into how to prevent data leakage in machine learning.
What is data leakage in machine learning?
Data leakage in machine learning is when information from the training set is used to improve the performance of the model on the test or validation set. This is a form of overfitting, where the model is too closely fitted to the training data. Data leakage can lead to models that appear to have good accuracy, but are not actually generalizable to new data.
What are the consequences of data leakage?
Data leakage can lead to models that are overly optimistic in terms of their performance. This means that the models will have good accuracy on the test set or validation set, but will not generalize well to unseen data. This can lead to models that perform poorly in the real world, as they do not have the ability to accurately predict outcomes with new data.
How can data leakage be avoided?
Data leakage can be avoided by ensuring that all data used in the training and validation process is properly partitioned and that the same data is not used in both processes. This can be done by using a separate data set for training and testing and ensuring that the same data is not used in both processes. Additionally, data leakage can be prevented by using techniques such as cross-validation, which involves splitting the data into multiple partitions and using different parts of the data for training and testing.
What techniques can be used to detect data leakage?
Data leakage can be detected by using techniques such as correlation analysis, which can be used to identify features that are strongly correlated with the target. Additionally, data leakage can be detected by using techniques such as information theoretic measures, which can be used to identify features that are highly predictive of the target.
What are the best practices for preventing data leakage?
The best practices for preventing data leakage include using proper data partitioning, using cross-validation to ensure that the same data is not used for both training and testing, and using information theoretic measures and correlation analysis to identify features that are highly predictive of the target. Additionally, it is important to ensure that all data used in the training and validation process is properly labeled and that the same labels are used for both processes. Finally, it is important to ensure that any data preprocessing is properly done and that the same preprocessing is applied to both the training and testing sets.

In conclusion, data leakage is a serious issue that can have lasting consequences for individuals and organizations alike. However, with the power of machine learning, there are steps you can take to prevent it from occurring. By implementing effective security measures such as encryption and access controls, you can safeguard your sensitive data and prevent unauthorized access.
Furthermore, it is important to stay up to date with the latest developments in machine learning, as these technologies can help you better understand and detect potential data leaks. With the right tools and strategies in place, you can protect your data from a wide range of threats and ensure that your organization remains secure and resilient in the face of today’s ever-evolving digital landscape. So, take the time to educate yourself on the best practices for preventing data leakage, and invest in the tools and technologies that will help you stay ahead of the curve. Your data – and your business – will thank you for it.