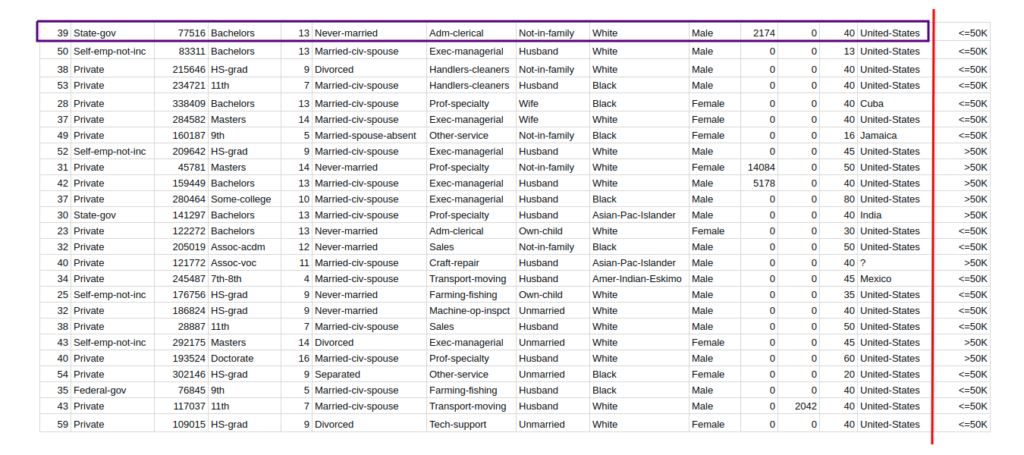
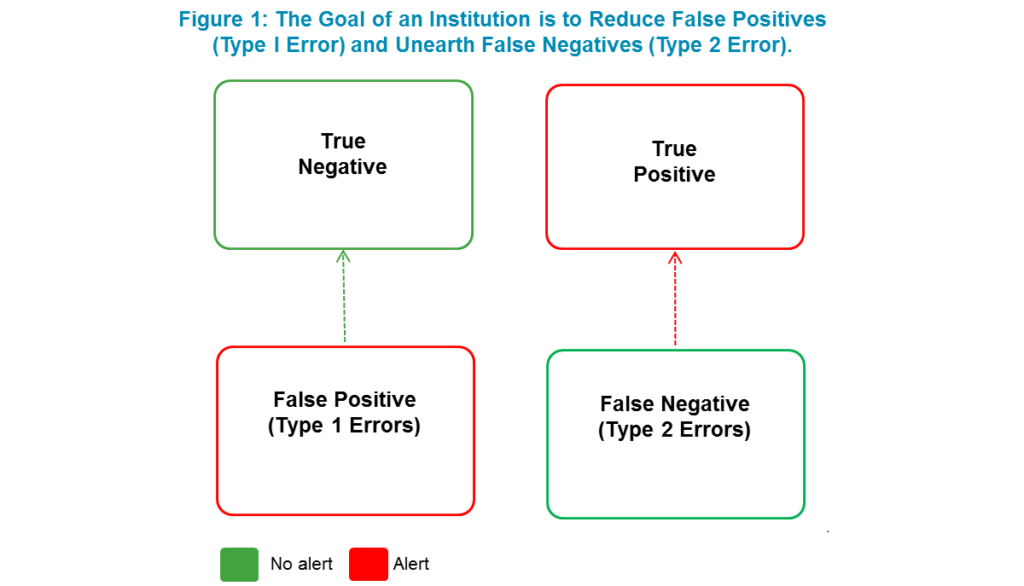
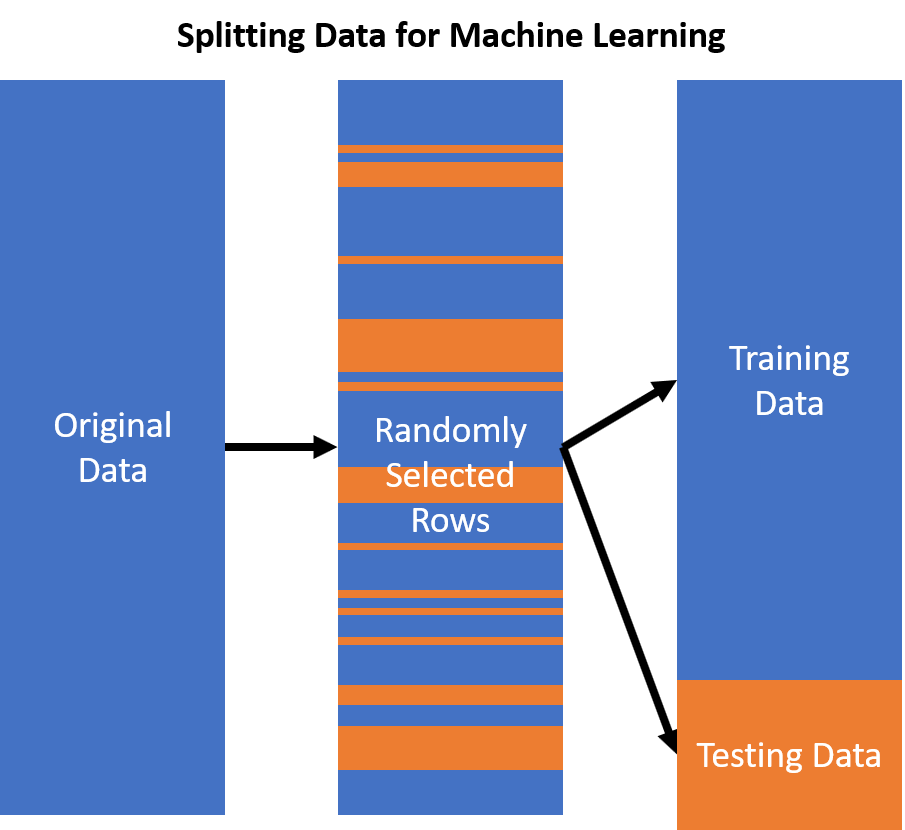
As the world becomes increasingly digitized, more and more data is being generated and analyzed by machines. This data is used to train machine learning algorithms and to make predictions about future outcomes. However, with the rise of big data comes the risk of data leakage.
Data leakage occurs when sensitive information is inadvertently disclosed to unauthorized parties. In the context of machine learning, this can happen when sensitive data is used to train algorithms or when predictions are made using data that should be kept confidential. Data leakage can have serious consequences, including loss of privacy, financial loss, and damage to a company’s reputation. In this article, we will explore what data leakage is in machine learning and how it can be prevented.
What is Data Leakage in Machine Learning?
Data leakage in machine learning is a phenomenon whereby the machine learning model learns patterns that are not present in the data and uses them to make predictions. This is generally due to a lack of data preprocessing, which results in the model “leaking” information that is not related to the task at hand. Data leakage can lead to inaccurate results, and can lead to overfitting, which is when a model performs very well on the training data, but poorly on the test data.
What Causes Data Leakage?
Data leakage can occur due to a number of factors, including improper data preprocessing, poor feature engineering, and inadequate data splitting. Data preprocessing involves cleaning and transforming the data, such as normalizing the data, removing outliers, and dealing with missing values. Feature engineering is the process of creating new features from existing ones, such as combining existing features to create a new one. Data splitting is the process of dividing the data into training and test sets, which helps to prevent the model from “seeing” the test data during training.
What are the Effects of Data Leakage?
Data leakage can lead to inaccurate results, as the model is learning patterns that are not present in the data. This can lead to overfitting, which is when a model performs very well on the training data, but poorly on the test data. Overfitting can also lead to poor generalization, which is when the model is not able to accurately make predictions on data that it has never seen before.
How to Prevent Data Leakage?
Data leakage can be prevented by ensuring proper data preprocessing, feature engineering, and data splitting. Data preprocessing should involve cleaning and transforming the data, such as normalizing the data, removing outliers, and dealing with missing values. Feature engineering should involve creating new features from existing ones, such as combining existing features to create a new one. Data splitting should involve dividing the data into training and test sets, which helps to prevent the model from “seeing” the test data during training. Additionally, cross-validation can be used to further reduce the risk of data leakage.
Frequently Asked Questions
Data leakage in machine learning is an issue that can potentially skew the results of a predictive model. It occurs when data from outside the training dataset is used to create the model, leading to results that are overly optimistic and not representative of the data or the problem being solved.
What is data leakage in machine learning?
Data leakage in machine learning is when data from outside the training dataset is used to create the model, leading to results that are not representative of the data or the problem being solved. This can have serious implications for the accuracy and reliability of the model, as it may not be able to accurately predict new outcomes or use the dataset to identify patterns. It can also lead to models that are overly optimistic, as they may not be able to account for real-world variables or account for the variability in the data.
Data leakage can come from a variety of sources, including external datasets, manual data entry, and even data that is provided by the data analyst or researcher. In some cases, it can even be the result of a data scientist or machine learning engineer inadvertently introducing data from outside the training dataset. It is important to identify and address any potential data leakage before the model is deployed, as it can lead to inaccurate results and potentially skewed predictions.
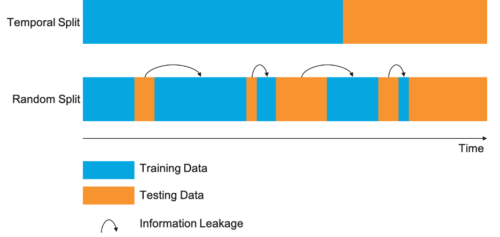
In conclusion, data leakage in machine learning is a critical issue that can significantly impact the accuracy and reliability of model predictions. It can arise from various sources, including incorporating irrelevant or redundant features, using information from the test set in the training process, or leaking sensitive information during data preprocessing. Therefore, it is essential for machine learning practitioners to be aware of the potential sources of data leakage and take appropriate measures to prevent it.
To avoid data leakage, machine learning practitioners should carefully analyze the data and identify potential sources of leakage. They should also adopt best practices such as using cross-validation, separating data into training and testing sets, and masking sensitive information during data preprocessing. By taking these steps, machine learning practitioners can ensure that their models are robust, reliable, and provide accurate predictions that are free from data leakage. Ultimately, preventing data leakage is crucial for ensuring the integrity of data-driven decisions in various domains, including finance, healthcare, and security.