
As technology continues to advance at an unprecedented pace, the world of artificial intelligence has become one of the most exciting and rapidly developing fields. One of the most recent and widely discussed developments in this field is GPT-3. This advanced AI system has been generating a lot of buzz due to its incredible language generation capabilities. However, many people are wondering what exactly GPT-3 is and what it has been trained on to achieve such impressive results.
GPT-3 stands for Generative Pre-trained Transformer 3, and it is a natural language processing system that has been trained on an enormous amount of data. This data includes everything from Wikipedia articles and news stories to social media posts and even books. The system has been designed to analyze and understand language at an incredibly deep level, allowing it to generate text that is often indistinguishable from human writing. In this article, we will explore what GPT-3 is, what it has been trained on, and how it is changing the landscape of artificial intelligence.
GPT-3 (Generative Pre-trained Transformer 3) is an artificial intelligence (AI) system developed by OpenAI that uses a large-scale unsupervised language model to produce human-like text. It was trained on a dataset of over 45TB of text, including web text, books, and other sources. GPT-3 enables applications such as natural language processing, question answering, dialogue generation, and more.
How To Use GPT-3?
- Choose the Type of Model – GPT-3 provides a range of models, from small to large.
- Integrate with Your Application – Connect GPT-3 to your application or tool using the API.
- Set the Input Parameters – Set the parameters based on the type of output you need.
- Generate Output – Use GPT-3 to generate output.
- Evaluate Output – Evaluate the output GPT-3 produces.
GPT-3 vs Other AI Systems
| GPT-3 | Other AI Systems |
|---|---|
| Unsupervised language model | Supervised learning algorithms |
| Uses 45TB of text data | Uses smaller datasets |
| More accurate and complex output | Less accurate and complex output |
| Can generate human-like text | Cannot generate human-like text |
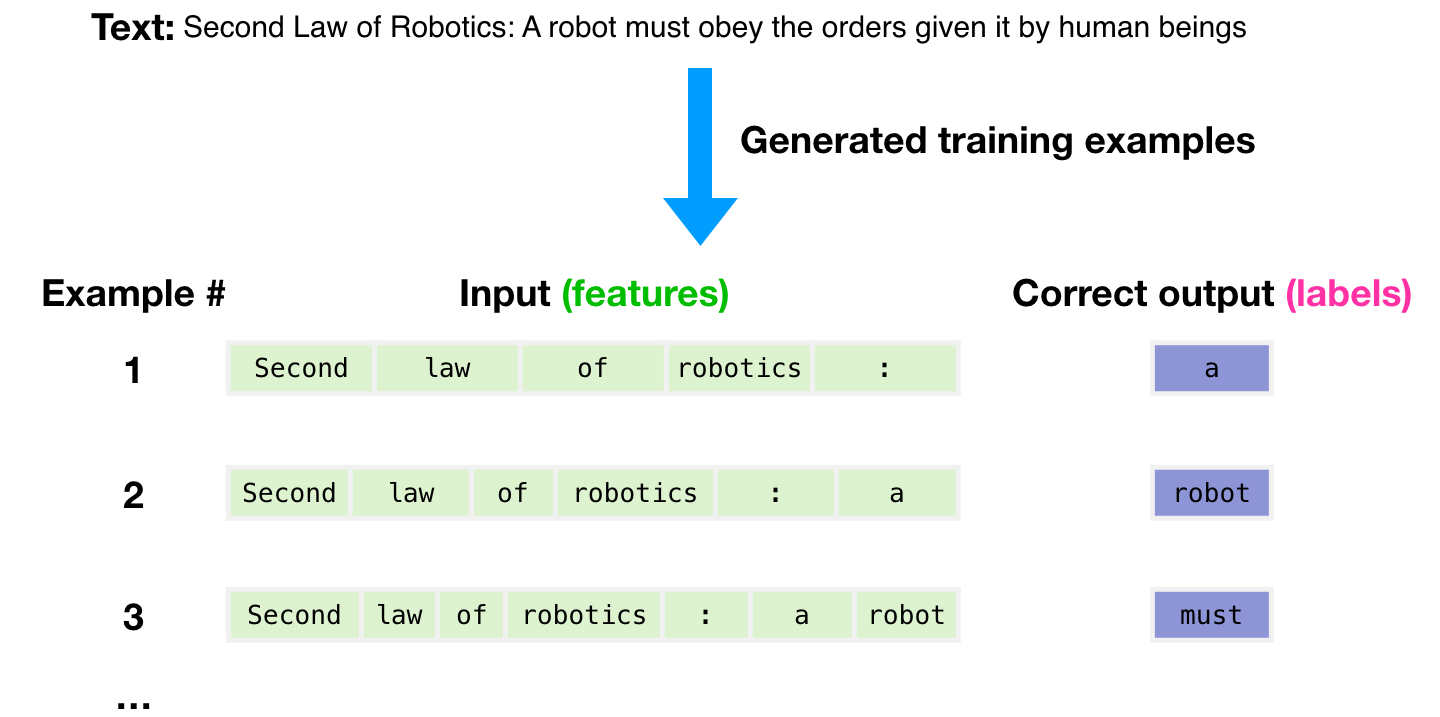
What is GPT-3?
GPT-3 (Generative Pre-trained Transformer 3) is a deep-learning language model developed by OpenAI. It is the successor to GPT-2, which was released in 2018. GPT-3 is designed to generate natural language from a prompt using deep learning algorithms. It is based on a transformer architecture, which is a type of neural network that is well suited for language modeling. GPT-3 is trained on a large dataset of text.
What was GPT-3 Trained On?
GPT-3 was trained on a massive dataset of text, containing more than 45TB of data. The dataset consists of text from a variety of sources, including books, news articles, blogs, and social media. GPT-3 is trained on the text in order to learn how to generate natural language given a prompt. The model is able to generate high-quality text that sounds natural and is grammatically correct.
Text Sources
GPT-3 is trained on text from a variety of sources. These include books, news articles, blogs, and social media. The model is trained on a massive dataset of text, containing more than 45TB of data. This dataset consists of text from a variety of sources, including books, news articles, blogs, and social media.
Natural Language Generation
GPT-3 is trained to generate natural language from a prompt. The model is able to generate high-quality text that sounds natural and is grammatically correct. The model is designed to take a prompt and generate a response that is relevant to the prompt. This allows the model to generate text that is related to a given topic or context. The model is also able to generate text that is appropriate for a given audience. For example, the model can generate text that is tailored to a particular age group or gender.
Frequently Asked Questions
GPT-3 is a powerful new language model developed by OpenAI that can generate human-like text. It was trained on a massive dataset of over 45 TB of text from sources such as Wikipedia, Common Crawl, and BooksCorpus.
What was GPT-3 trained on?
GPT-3 was trained on a huge dataset of over 45 TB of text, which is an unprecedented amount of data for a language model. The dataset was sourced from a variety of sources, including Wikipedia, Common Crawl, and BooksCorpus. This allows GPT-3 to be trained on a wide variety of topics and styles, giving it a more natural feel when generating text.
The training dataset also includes a large number of different languages, which means that GPT-3 can generate text in a variety of languages. This makes GPT-3 a powerful tool for many different applications, from natural-language processing to question-answering systems.
In conclusion, GPT-3 is a technological marvel that has been trained on a vast corpus of data to produce human-like language. It has the potential to revolutionize the world of natural language processing and usher in a new era of intelligent machines. Despite its limitations and ethical considerations, GPT-3 marks a significant milestone in the field of artificial intelligence and will undoubtedly pave the way for future advancements.
As we continue to explore the capabilities of GPT-3, it is important to remember that it is not a replacement for human intelligence, but rather a tool that can aid us in our endeavors. Its ability to generate coherent and contextually relevant text is truly remarkable, and it is exciting to think about the possibilities that lie ahead. Whether it is used to improve language translation, assist in content creation or even help us communicate more effectively with one another, GPT-3 is a step towards a more intelligent and connected world.


