Machine learning is a rapidly growing field that has revolutionized the way we approach data analysis and decision-making. With the vast amount of data available, it is essential to have a model that can accurately predict outcomes and make informed decisions. However, choosing the best model in machine learning can be a daunting task, especially for those who are new to the field.
The key to selecting the best model in machine learning is to understand the problem you are trying to solve and the data you are working with. There are many different types of models to choose from, each with its own strengths and weaknesses. In this article, we will explore the different types of models in machine learning and provide tips on how to choose the best one for your specific needs. By the end of this article, you will have a better understanding of how to select the right model to get the best results.
.jpg)
How to Choose the Best Model in Machine Learning?
The ability to choose the best model in machine learning is essential for building successful machine learning applications. Knowing how to select the right model for each task and understanding the different types of models available can help you make the right decision when it comes to selecting the best model for your project. In this article, we’ll discuss the key considerations and steps to choosing the best model for your machine learning applications.
Understand the Types of Models Available
Before selecting a model, it’s important to understand the different types of models available. The most common types of models include linear and logistic regression, decision trees, support vector machines, and neural networks. Each type of model has its own strengths and weaknesses and can be used in different types of applications. For example, linear and logistic regression are best suited for linear problems, while decision trees are better for more complex, non-linear problems.
Understanding the different types of models available and their strengths and weaknesses can help you determine which model is most appropriate for your task. Additionally, certain models may be better suited for certain data types. For example, neural networks are well-suited for image processing tasks and decision trees can be used for text-based applications.
Assess Your Data
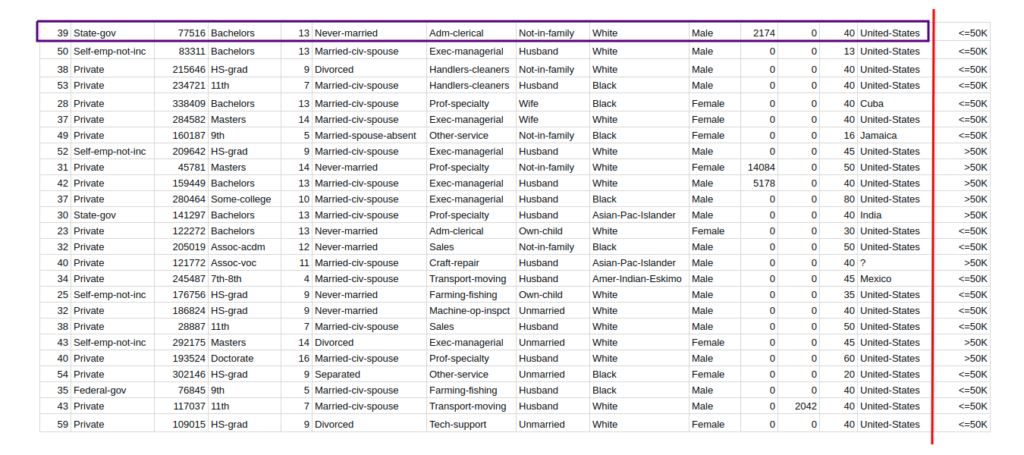
Once you’ve identified the types of models available, the next step is to assess your data. This includes determining the size, shape, and type of the data you’re working with. Understanding the characteristics of your data is essential for selecting the right model. For example, if you’re working with a large dataset, you may need to use a model that can handle large amounts of data. Additionally, if you’re working with a highly unstructured dataset, you may need to use a more complex model such as a neural network.
Additionally, you’ll want to consider the accuracy and performance of the model. Different models may have different accuracy and performance levels, so it’s important to determine which model will provide the best results for your specific task.
Test Different Models
Once you’ve identified the types of models available and assessed your data, the next step is to test different models. This involves splitting your dataset into training and testing sets, training different models on the training set, and then evaluating the models on the test set. This will help you determine which model provides the best results for your task.
It’s also important to consider the time it takes to train and evaluate each model. Certain models may take longer to train than others, so it’s important to consider the time available for training when selecting a model. Additionally, some models may require more resources such as memory or compute power than others, so it’s important to factor these resources into your decision.
Evaluate the Results
Once you’ve tested different models on your dataset, you’ll want to evaluate the results. This involves looking at the accuracy of the model as well as the performance of the model. Additionally, it’s important to consider the complexity of the model and the resources it requires.
Additionally, it’s important to consider the interpretability of the model. Certain models, such as decision trees, may be more interpretable than others, making them easier to explain and understand. This can be important for certain applications, such as healthcare, where it’s important to be able to explain the model’s decisions.
Choose the Best Model
Once you’ve evaluated the results of the different models, it’s time to select the best model for your task. This involves considering the accuracy, performance, complexity, and interpretability of the different models and selecting the one that best meets your needs. Additionally, it’s important to consider the resources required by the model, as well as the time it takes to train and evaluate the model.
By understanding the different types of models available, assessing your data, testing different models, and evaluating the results, you can make an informed decision on which model is best for your task. This will help you ensure that your machine learning applications are successful and provide the best results.
Frequently Asked Questions
This section provides answers to some of the most commonly asked questions about how to choose the best model in machine learning.
What is the process of choosing the best model in machine learning?
Choosing the best model in machine learning is a complex decision-making process. It involves not only selecting the most suitable model for the task, but also tuning hyperparameters and optimising the model’s performance. The process starts with selecting a model that best fits the given task. Generally, this is done by comparing the results of various models. After selecting the model, the next step is to tune its hyperparameters. This is done through a process of trial and error, where different combinations of hyperparameters are tested and the one with the best performance is chosen. Finally, the optimisation of the model’s performance is done by using techniques such as regularisation, which can reduce the effect of overfitting.
What are the most important factors to consider when choosing a model?
When choosing a model for a particular task, there are several important factors to consider. Firstly, the model should be suitable for the given task. This means that the model should have the necessary features and capabilities to solve the problem. Secondly, the model’s performance should be evaluated against a set of performance metrics. This will give an indication of how well the model performs on the given task. Thirdly, the model should be able to generalise well to unseen data. Finally, the model should be able to be deployed in a real-world environment.
What are the most popular machine learning models?
The most popular machine learning models are neural networks, support vector machines, random forests, decision trees, and deep learning. Neural networks are used for image recognition and natural language processing. Support vector machines are used for classification and regression tasks. Random forests are used for predicting outcomes based on a set of features. Decision trees are used for classification and regression tasks. Finally, deep learning is used for complex tasks such as image and speech recognition.
What techniques can be used to optimise model performance?
There are various techniques that can be used to optimise model performance. These include regularisation, which is a technique used to reduce the effect of overfitting on the model. Dropout is a technique that can be used to reduce the complexity of the model by randomly dropping some of the neurons in the network. Feature selection is a technique used to select the most relevant features from a dataset. Finally, hyperparameter tuning is a technique used to find the optimal combination of hyperparameters that will give the best performance.
How can I evaluate a model’s performance?
Evaluating a model’s performance is an important part of the process of choosing the best model. It involves comparing the model’s performance to a set of metrics. This can be done by using metrics such as accuracy, precision, recall, and the F1 score. The accuracy of the model is a measure of how well it can predict the correct label for a given data point. The precision and recall measures are used to measure the model’s ability to correctly identify positive and negative examples. Finally, the F1 score is a measure of the model’s overall performance.
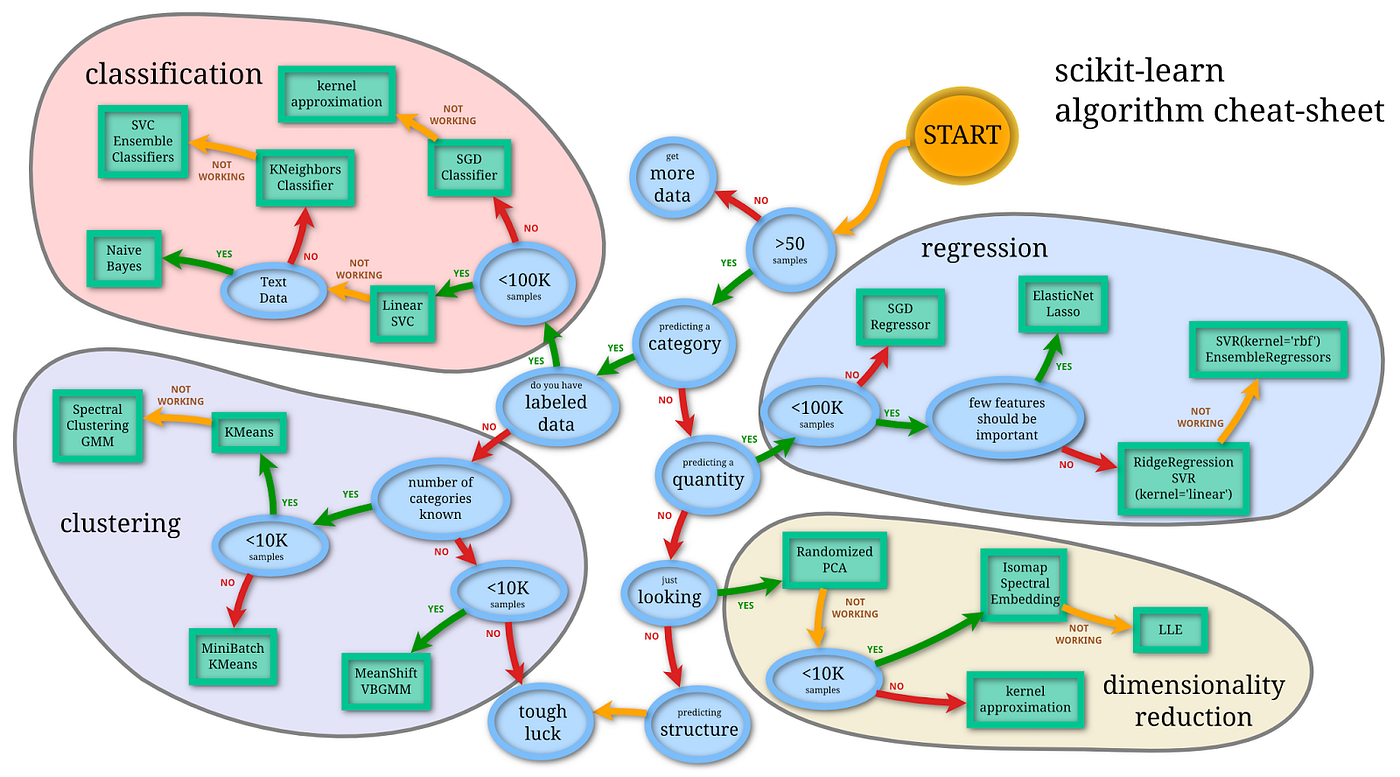
In conclusion, choosing the best model in machine learning requires a deep understanding of the problem at hand, the available data, and the specific goals of the project. It is not a one-size-fits-all approach, and there are various factors to consider, such as the complexity of the model, the amount of data available, and the accuracy and interpretability of the results. However, with the right approach and a willingness to experiment and iterate, it is possible to choose a model that will yield the most accurate and beneficial results for your project.
In the ever-evolving world of machine learning, it is crucial to stay up-to-date with the latest advancements and techniques. As new models and algorithms are developed, it is important to continue learning and experimenting to improve the accuracy and efficiency of your machine learning projects. By following best practices and staying informed, you can confidently choose the best model for your specific needs and make informed decisions that will lead to successful outcomes. Remember, the key to success in machine learning is not just choosing the right model, but also continuously refining and improving your approach to stay ahead of the curve.