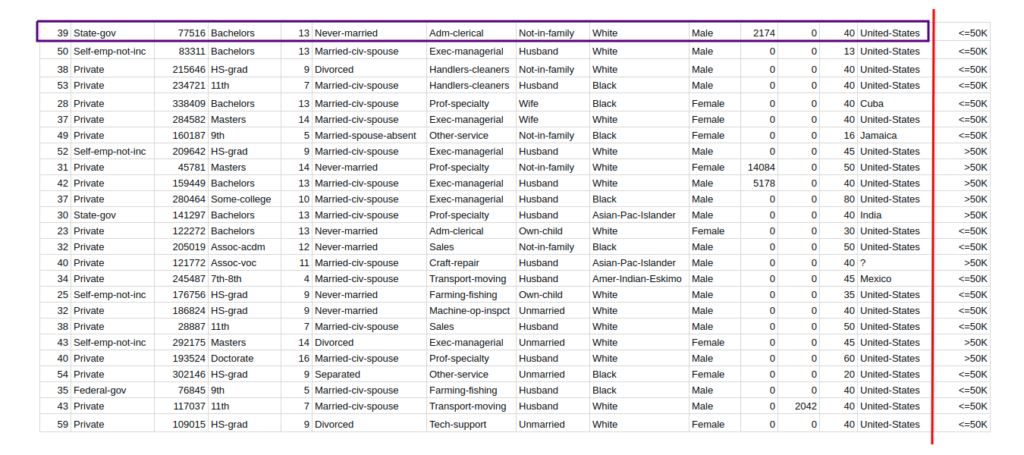
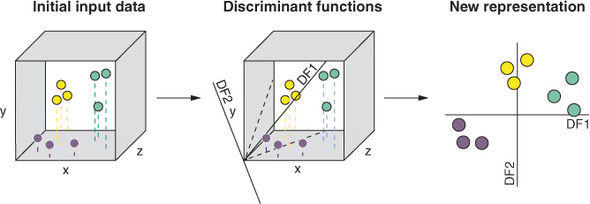
In the world of machine learning, data is king. Without quality data, machine learning algorithms cannot produce accurate predictions or insights. Collecting data is not a one-size-fits-all approach, as each project will have unique data requirements. However, there are some fundamental principles and best practices that can help ensure the success of data collection efforts.
In this guide, we will explore the various methods and techniques for collecting data for machine learning. From the different types of data sources to the tools and technologies used in data collection, we’ll provide you with the knowledge and skills needed to collect and prepare high-quality data for your machine learning projects. Whether you’re a data scientist, machine learning engineer, or developer, this guide will help you develop a solid understanding of the data collection process and enable you to build more accurate and effective machine learning models.
Collecting data for machine learning is an essential step to building an effective model. Here are the steps you need to take to collect the right data:
- Determine the data you need – identify the parameters you need to collect and what type of data will best fit those parameters.
- Find the data sources – locate the databases, websites, or other sources that have the data you need.
- Gather the data – use web scraping, APIs, or other methods to extract the data from the sources.
- Clean and organize the data – remove any irrelevant data, combine datasets, and organize the data in a relation database.
- Analyze the data – use exploratory data analysis to better understand the structure and trends of your data.
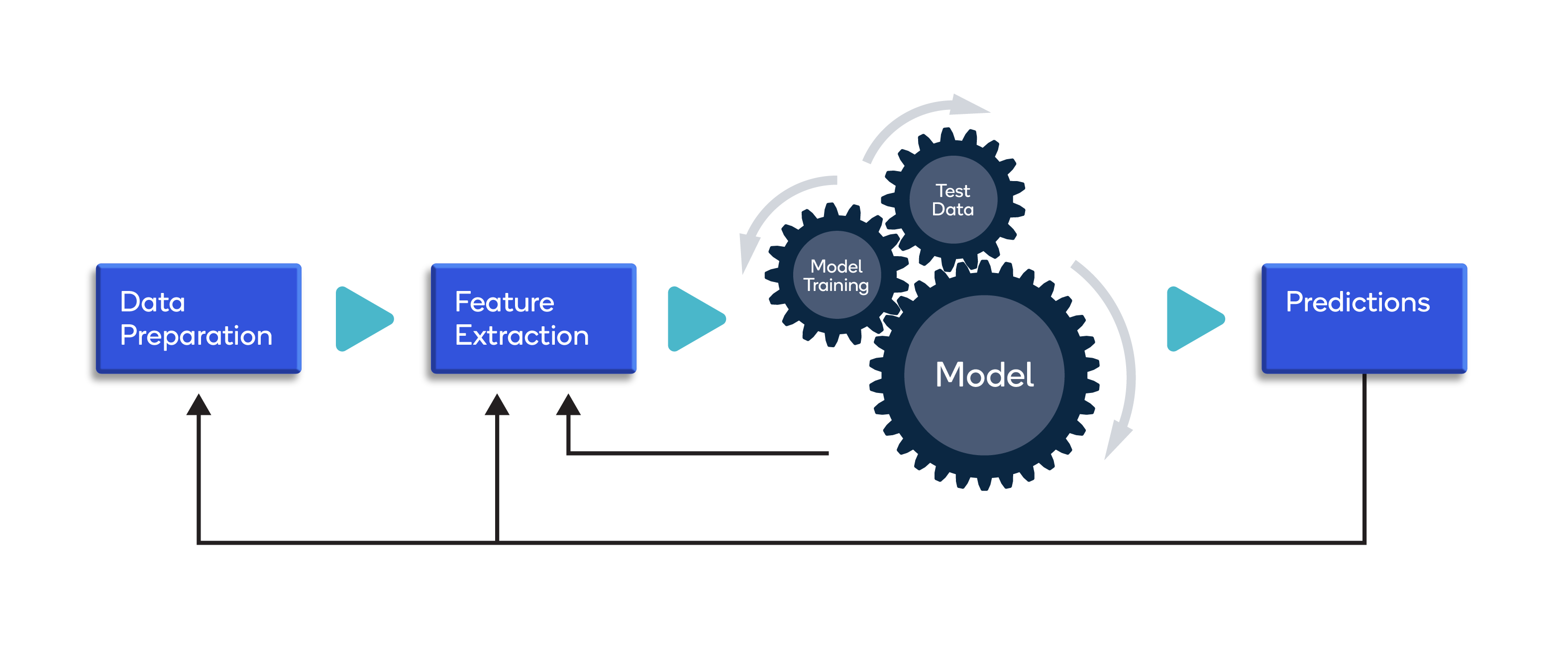
Introduction to Collecting Data for Machine Learning
Data collection is an essential part of machine learning. It involves gathering, organizing, and labeling data in order to construct a data set that is suitable for machine learning algorithms. This data can be used to train, test, and validate machine learning models. In this article, we will discuss the various methods of collecting data for machine learning and how to best go about it.
Methods of Collecting Data for Machine Learning
When it comes to collecting data for machine learning, there are three main methods that can be employed: scraping, crowdsourcing, and manual data entry. Each of these methods has its own strengths and weaknesses, and it is important to understand which method is best suited to the task at hand.
Scraping
Scraping is the process of extracting data from websites and other sources. This is done by writing scripts or programs that can crawl over websites, find the relevant data, and extract it. Scraping can be a time-consuming process, but it is often the most efficient way to collect large amounts of data quickly. Additionally, there are a number of tools and services that can simplify the process of web scraping.
Crowdsourcing
Crowdsourcing is the process of outsourcing tasks to a large group of people. This is often used to collect data in a cost-effective manner. Crowdsourcing can be a great way to quickly collect large amounts of data from a variety of sources. Additionally, it can be used to provide feedback on a particular task, or to gain insights from a large group of people.
Manual Data Entry
Manual data entry is the process of manually entering data into a database or spreadsheet. This is often used when the data is too complex or too large to be scraped or collected through crowdsourcing. Manual data entry can be a time-consuming process, but it is often the most accurate way to collect data.
Data Labeling
Data labeling is the process of labeling data so that it can be easily identified and used. This is often done by assigning tags or labels to the data in order to categorize it. Data labeling is an essential part of preparing data for machine learning algorithms.
Data Cleansing and Preprocessing
Data cleansing and preprocessing is the process of cleaning and preparing data for machine learning algorithms. This involves removing any unnecessary or irrelevant data, as well as formatting the data in a way that is more suitable for machine learning algorithms. Data cleansing and preprocessing are essential for ensuring that the data is suitable for machine learning algorithms.
Data Aggregation
Data aggregation is the process of combining data from multiple sources in order to create a single data set. This is often done in order to gain insights from a variety of sources. Data aggregation can be done manually or through automated processes, and it is often used to create larger data sets that can be used for machine learning algorithms.
Data Visualization
Data visualization is the process of creating visual representations of data. This can be done in order to gain insights from the data or to make it easier to interpret. Data visualization can be used to gain insights from large amounts of data or to make complex datasets easier to understand.
Data Storage
Data storage is the process of storing data in a secure and organized manner. This is often done in order to ensure that the data is safe and accessible. Data storage can be done on a local machine, on a cloud-based platform, or in a dedicated database.
Frequently Asked Questions
Here you will find answers to the most common questions about collecting data for machine learning.
What is data collection?
Data collection is the process of gathering, organizing, and analyzing information from various sources in order to make informed decisions. Data collection can be done manually or through automated methods such as surveys, web scraping, and data mining. Data collection is an important step in the machine learning process, as it helps to identify patterns and trends in the data that can be used to develop machine learning models.
How is data collected for machine learning?
Data for machine learning can be collected in a variety of ways. The most common methods are manually entering data into a database, using surveys to collect data from users, and using web scraping techniques to collect data from websites. Additionally, data can be collected through data mining, which involves searching through large volumes of data to identify patterns and trends.
What types of data are used for machine learning?
The types of data used for machine learning depend on the type of machine learning model being developed. Common types of data used for machine learning include numerical data, categorical data, text data, and image data. Additionally, time-series data can be used to develop models that predict future trends or patterns.
What are some best practices for collecting data for machine learning?
When collecting data for machine learning, it is important to ensure that the data is accurate, up-to-date, and relevant to the task at hand. Additionally, it is important to collect a sufficient amount of data, as machine learning models require large datasets in order to be effective. It is also important to ensure that the data is properly labeled and organized.
How can data be stored for machine learning?
Data for machine learning can be stored in a variety of ways. Common methods for storing data include using a database, using a data warehouse, or using a cloud storage service. Additionally, it is important to ensure that the data is secured so that it is not accessible to unauthorized users.

In conclusion, collecting data for machine learning is a crucial step in building successful models. It requires patience, perseverance, and the right approach to ensure that the data collected is of high quality and relevant to the problem at hand. Whether you are collecting data from online sources, through surveys, or by scraping websites, it is important to verify the accuracy of the data and ensure that it is unbiased. Furthermore, cleaning and preprocessing the data is vital to improve the accuracy of the model and prevent errors.
As machine learning continues to drive innovation in various industries, collecting data will remain a critical component of the process. By following the best practices and tips outlined in this article, you can ensure that your data collection process is efficient, effective, and yields the desired results. Remember to continually evaluate and improve your data collection methods to stay ahead in the competitive world of machine learning. With the right approach, collecting data can be an exciting and rewarding experience that ultimately leads to the development of powerful and impactful models that drive positive change.