Machine learning has emerged as a powerful tool for businesses and organizations to make informed decisions and gain insights into their operations. However, with the vast amounts of data that are processed and analyzed, there is a risk of data leakage. Data leakage can occur when sensitive information is inadvertently disclosed or accessed by unauthorized parties. This can lead to data breaches, financial losses, and reputational damage. As such, it is essential for organizations to take proactive steps to prevent data leakage in machine learning.
In this article, we will explore some of the key strategies that organizations can adopt to mitigate the risk of data leakage in machine learning. From data anonymization and access controls to encryption and monitoring, we will delve into the best practices and tools that can help organizations keep their data secure. Whether you are a data scientist or a business owner, this article will provide valuable insights on how to safeguard your sensitive data and reap the benefits of machine learning without compromising privacy and security.
To avoid data leakage in machine learning, the following steps should be taken:
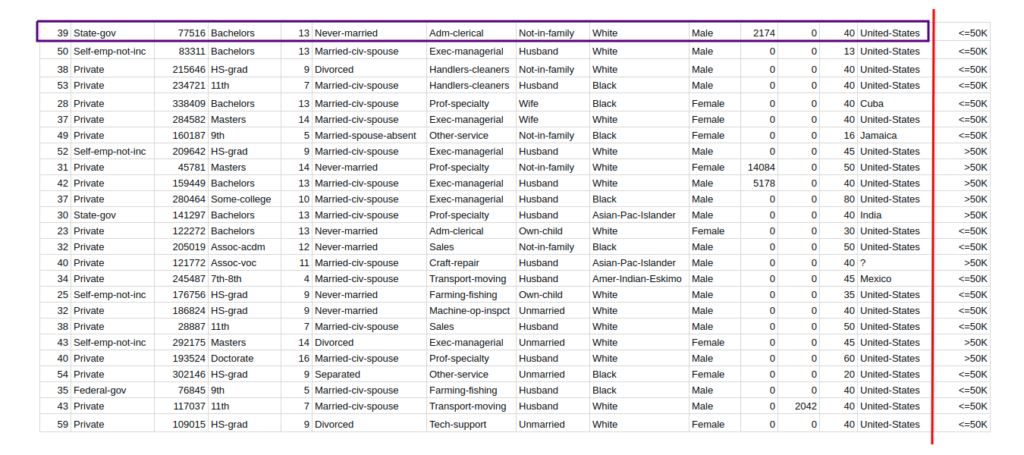
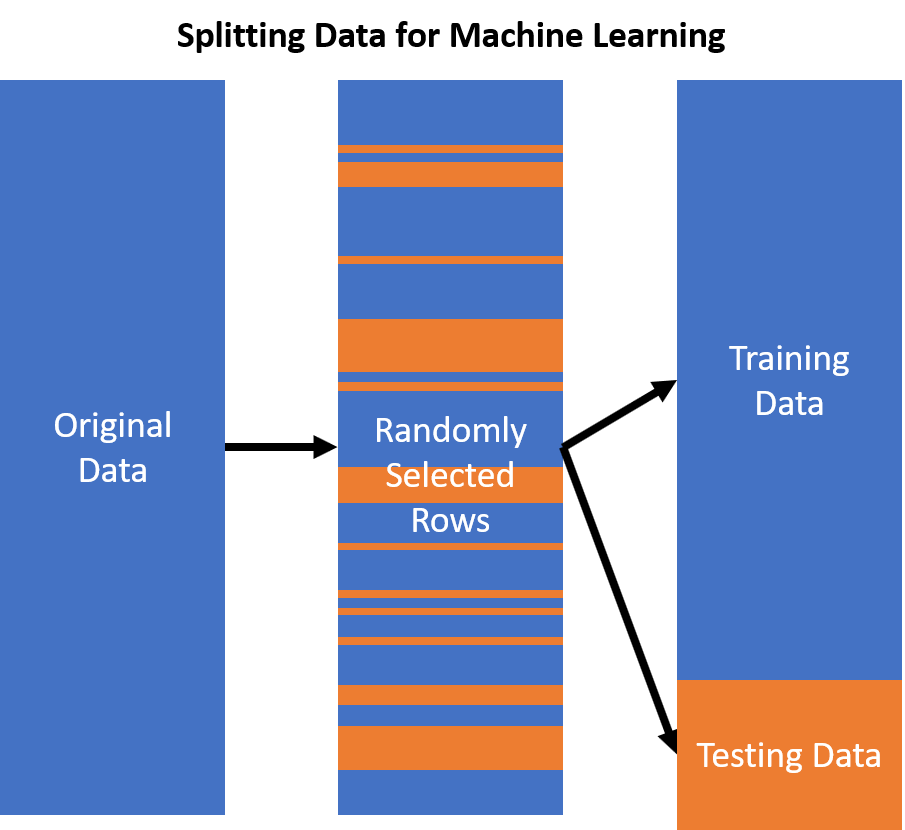
- Organize data into train and test set, with the former containing the data used to train the model, and the latter containing the data to evaluate the trained model.
- Check for data leakage in the model’s features. If any of the features contain data that was not present in the training set, then this will bias the model and lead to overfitting.
- Check for any leakage between the training and test sets. If data from the training set is present in the test set, then this will bias the model and lead to overfitting.
- Check for any leakage between the target variable and the features. If the target variable contains information that is present in the features, then this will bias the model and lead to overfitting.
- Check for any leakage between the training and validation sets. If data from the training set is present in the validation set, then this will bias the model and lead to overfitting.
How to Avoid Data Leakage in Machine Learning
What is Data Leakage?
Data Leakage is a phenomenon where data is accessed, shared, or leaked without authorization. Data leakage in machine learning occurs when an algorithm is exposed to data that is not part of the training set. This can lead to false results and inaccurate predictions.
Data leakage can be caused by a variety of factors, including overfitting, underfitting, and improper data pre-processing. Overfitting occurs when an algorithm is exposed to too much data and performs too well on the training set but not on the test set. Underfitting occurs when an algorithm is exposed to too little data and performs poorly on the training set and test set. Improper data pre-processing can cause data leakage by introducing bias or noise to the training data.
Steps for Avoiding Data Leakage
The best way to avoid data leakage in machine learning is to employ a proper data pre-processing strategy. Data pre-processing involves cleaning the data, scaling it, and normalizing it. This ensures that the data is accurate and free from any bias. Additionally, it is important to split the data into training and test sets. This allows for the algorithm to be tested on unseen data and ensures that the model is not overfitting or underfitting.
In addition to data pre-processing, it is important to use proper cross-validation techniques. Cross-validation involves splitting the data into training and validation sets and then testing the model on the validation set. This helps to ensure that the model is not overfitting or underfitting on the training set.
Data Leakage Detection
Data leakage detection is an important part of avoiding data leakage in machine learning. Data leakage detection involves monitoring the data and algorithm performance to detect any signs of data leakage. This can be done by monitoring the accuracy of the model on the training and test sets, and by monitoring any changes in the data over time.
Data leakage detection can also be done using automated tools. Automated tools can detect anomalies in the data and alert the user to any potential data leakage. Additionally, automated tools can be used to detect any changes in the training data that could lead to data leakage.
Conclusion
Data leakage in machine learning can lead to inaccurate results and false predictions. To avoid data leakage, it is important to employ a proper data pre-processing strategy and use proper cross-validation techniques. Additionally, data leakage detection should be implemented to monitor the data and algorithm performance and detect any signs of data leakage. By implementing these strategies, machine learning practitioners can ensure that their models are not exposed to any unauthorized data.
Frequently Asked Questions
Data leakage is a major concern in the field of machine learning. It can lead to inaccurate predictions and decreased accuracy of models. Here are some frequently asked questions about how to avoid data leakage in machine learning.
What is data leakage?
Data leakage is the introduction of information into a machine learning model that is not available to the model at the time of training. It can occur when data is incorrectly used in the training process, or when information not available at the time of training is used to make predictions. Data leakage can lead to inaccurate predictions, decreased model accuracy, and an overall decrease in the quality of the model.
How can data leakage be prevented?
Data leakage can be prevented by ensuring that the data used to train a model is clean and accurate. This includes ensuring that there are no missing values and that the data is up-to-date. Additionally, data should be split into training and test sets, and the test set should be held out and not used in the training process. This way, any information that is not available to the model at the time of training will not affect the accuracy of the model.
What techniques can be used to detect data leakage?
Data leakage can be detected through the use of techniques such as cross-validation and outlier detection. Cross-validation is a method of testing the accuracy of a model on a different set of data than the one used to train it. Outlier detection can be used to identify any potential data points that may have been incorrectly used in the training process.
What are the consequences of data leakage?
The consequences of data leakage can range from decreased accuracy of the model to inaccurate predictions. Data leakage can also lead to an overall decrease in the quality of the model, as well as an increase in the risk of overfitting.
How can data leakage be avoided in the future?
Data leakage can be avoided in the future by ensuring that data is clean and accurate, and by using techniques such as cross-validation and outlier detection. Additionally, data should be split into training and test sets, and the test set should be held out and not used in the training process. This will help to ensure that any information not available to the model at the time of training does not affect the accuracy of the model.

In conclusion, data leakage is a serious issue that can threaten the reliability and accuracy of machine learning models. As a professional in the field, it is important to understand the causes and potential consequences of data leakage, and take proactive measures to prevent it. By implementing strict data management protocols, carefully selecting and pre-processing data, and regularly monitoring models for signs of leakage, machine learning practitioners can ensure that their models remain trustworthy and effective tools for making data-driven decisions.
As the field of machine learning continues to grow and evolve, it is likely that new techniques for detecting and preventing data leakage will emerge. However, the best defense against data leakage will always be a combination of human diligence and technical expertise. By remaining vigilant and informed about the latest developments in the field, machine learning professionals can continue to push the boundaries of what is possible with this powerful technology, while minimizing the risks of unintended consequences. Ultimately, by working together to address the challenge of data leakage, we can help to ensure that machine learning remains a force for good in the world.