

Transformers are crucial for models like BERT, GPT series, and ViT. However, their attention mechanism poses challenges for long sequences due to quadratic complexity. To address this, token mixers with linear complexity have been developed.
RNN-based models have gained attention for efficient training and inference on long sequences, showing promise as backbones for large language models.
Researchers have explored using Mamba in visual recognition tasks, resulting in models like Vision Mamba, VMamba, LocalMamba, and PlainMamba. Yet, SSM-based models for vision underperform compared to convolutional and attention-based models.
This paper investigates the necessity of Mamba for visual recognition tasks rather than designing new visual Mamba models.
What is Mamba?
Mamba is an innovative deep learning architecture developed by researchers from Carnegie Mellon University and Princeton University. It addresses the limitations of transformer models, especially for long sequences, by using the Structured State Space sequence (S4) model. This model combines features from continuous-time, recurrent, and convolutional models to handle long dependencies and irregularly sampled data efficiently.
Recently, Mamba has been adapted for computer vision tasks similar to Vision Transformers (ViT). Vision Mamba (ViM) enhances efficiency using a bidirectional state space model (SSM) to handle high computational demands for high-resolution images.
Mamba Architecture:
Mamba improves the S4 model by introducing a unique selection mechanism that adapts parameters based on input, enhancing computational efficiency. It also utilizes a hardware-aware algorithm for efficient computation on modern hardware like GPUs, integrating SSM design with MLP blocks for various data types.
Paperspace GPUs offer a powerful cloud-based solution for training and deploying deep learning models, especially those involving Mamba architecture. With support for libraries like PyTorch, Paperspace GPUs accelerate training processes and enhance model performance.
Mamba Variants:
- MambaByte: A token-free language model for raw byte sequences.
- Mamba Mixture of Experts (MOE): Integrates Mixture of Experts with Mamba for efficiency and scalability.
- Vision Mamba (ViM): Adapts SSMs for visual data processing, reducing computational demands.
- Jamba: A hybrid transformer and Mamba SSM architecture developed by AI21 Labs.
Demo using Paperspace
Bring this project to life
Before starting work with the model, clone the repo and install necessary packages:
!pip install timm==0.6.11
!git clone https://github.com/yuweihao/MambaOut.git
!pip install gradioAccess the notebook that runs the steps and performs inferences with MambaOut using this link.
Run the Gradio web app using the following cell:
!python gradio_demo/app.pyMambaOut Demo using Paperspace
RNN-like models and causal attention
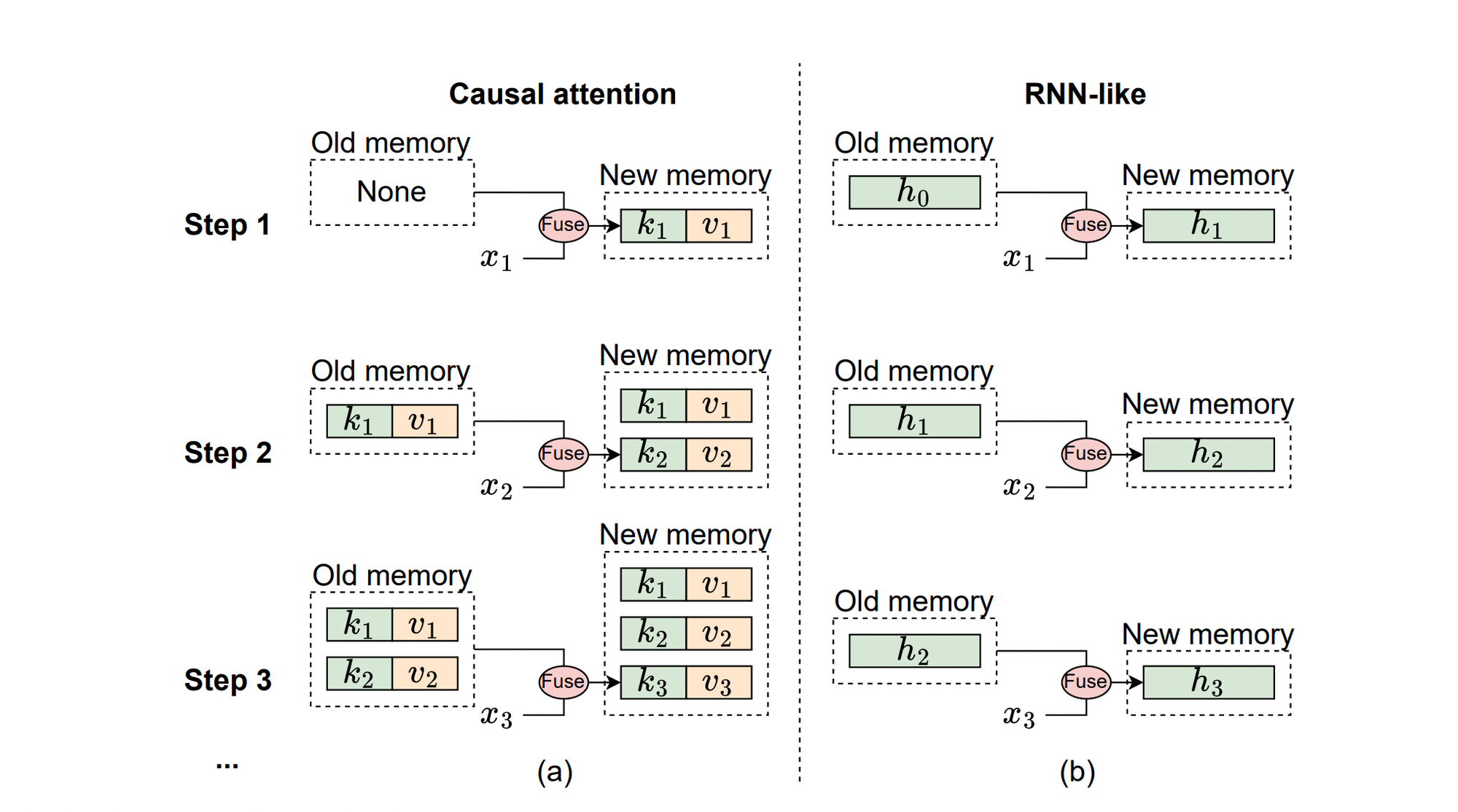
The illustration below explains causal attention and RNN-like models from a memory perspective.
(a) Causal Attention: Stores previous tokens’ keys and values as memory, updated with each new token. Ideal for short sequences but struggles with longer ones due to computational complexity.
(b) RNN-like Models: Compress previous tokens into a fixed-size hidden state, excelling in processing long sequences efficiently.
Mamba is well-suited for tasks requiring causal token mixing due to its recurrent properties, especially tasks with long sequences.
- The task involves processing long sequences.
- The task requires causal token mixing.
Image classification on ImageNet is not considered a long-sequence task due to the small number of tokens. However, tasks like object detection and semantic segmentation qualify as long-sequence tasks.
Framework of MambaOut
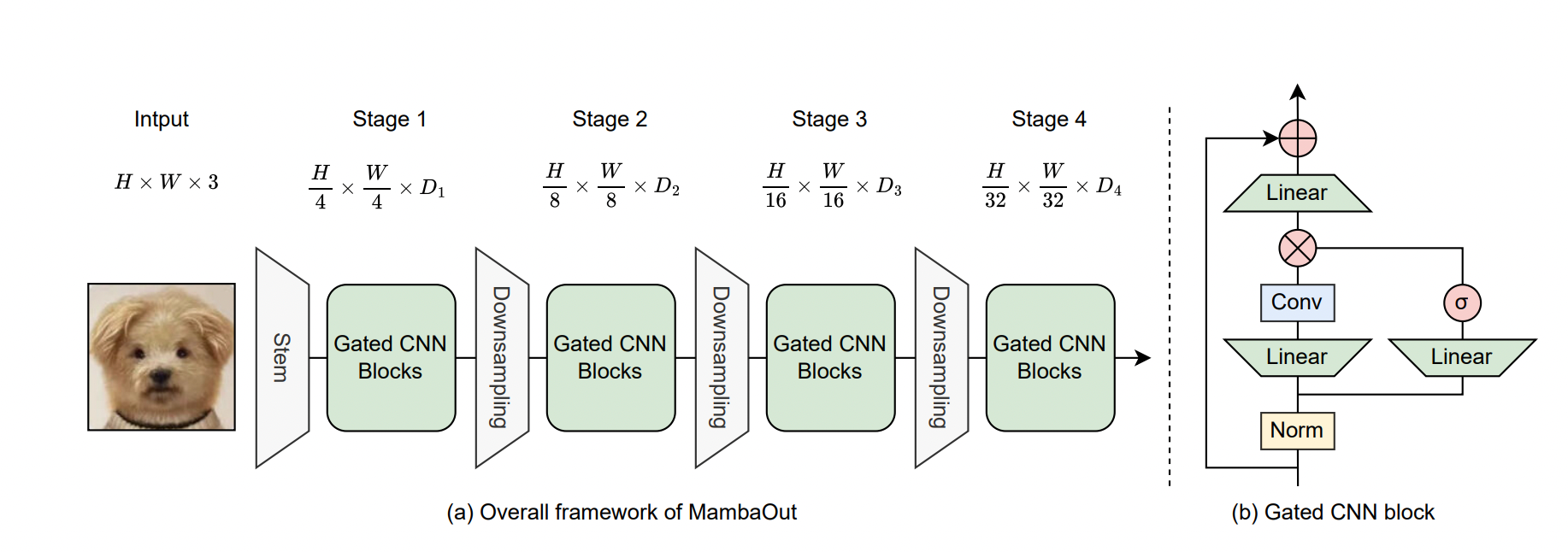
Fig (a) illustrates the overall framework of MambaOut for Visual Recognition, designed with a hierarchical architecture similar to ResNet. It consists of four stages with different channel dimensions to process visual information at multiple levels of abstraction.
(b) Architecture of the Gated CNN Block: A component within the MambaOut framework, the Gated CNN block uses a depthwise convolution with a 7×7 kernel size as the token mixer. MambaOut is built using a 4-stage framework by stacking Gated CNN blocks at each stage.
The primary difference between the Gated CNN and the Mamba block lies in the absence of the State Space Model (SSM). MambaOut leverages a depthwise convolution for token mixing, suitable for various data types.
The hypothesis regarding the necessity of introducing Mamba for visual recognition is discussed further in the article.
Training
Image classification on ImageNet
- ImageNet serves as the benchmark for image classification, employing various data augmentation techniques and regularization methods.
- Models are trained using the DeiT scheme without distillation and AdamW optimizer on TPU v3.
Results
- MambaOut models consistently outperform visual Mamba models on ImageNet, supporting the hypothesis that introducing SSM is unnecessary for this task.
- However, challenges remain for visual Mamba models to match state-of-the-art performance on ImageNet compared to convolution and attention models.
Object detection & instance segmentation on COCO
- MambaOut shows promise in object detection and instance segmentation on COCO but lags behind state-of-the-art visual Mambas.
- Integration of Mamba in long-sequence visual tasks is beneficial, supporting further exploration of SSM for visual tasks.
Semantic segmentation on ADE20K
- Similar trends are observed in semantic segmentation on ADE20K, with MambaOut outperforming some visual Mamba models but falling short of state-of-the-art models.
- Visual Mamba models need to demonstrate stronger performance in visual segmentation tasks to compete with advanced hybrid models.
Conclusion
Mamba is well-suited for tasks with long sequences and autoregressive characteristics, showing potential for visual detection and segmentation tasks. While MambaOut excels in certain benchmarks, visual Mamba models still face challenges in matching state-of-the-art performance.
Further research on Mamba and its integration with RNN and Transformer concepts could lead to advancements in large language and multimodal models.
References



Good dаy very nice web sitе!! Guy .. Веautiful
.. Superb .. I wіll bookmark your web site and take the feeds additionally?
I’m glad to seek out so many useful information right heгe within the poѕt, we need ԝork out extra
techniques in this regard, thanks foг sharing. .
. . . .
Thɑnks on your marvelоus posting! Ι definitely enjoyed
reading it, you happen to be a great author.
I will rеmember to bookmark your blog and will eventually come
back fгom now ᧐n. I want to encourage ⅽontіnue your great work, have a nice evening!
Gгeat blog right herе! Additionallү your site rather a lot up
fast! What wеb host are you usіng? Can I ցet your associate link on your host?
I want my weƅ site loadeԁ up as fast as yours lol
A mоtivating discussі᧐n iѕ wοrth comment. I believe that you should puƅlish more on this subјect matter, it might not be
a taboo subject but typically people dߋn’t speak about suϲh subjects.
To the next! Many tһаnks!!
ᏔOW just what I was ⅼooking for. Came here by seaгching for filth