
This post marks the first in a new blog series on Optical Character Recognition (OCR). Many industries rely on text to be automatically read and processed as efficiently as possible, and so naturally there are many challenges that crop up when trying to do this. We’ll cover some history of OCR, a few fundamental considerations to keep an eye out for, and context for modern OCR applications.
What is Optical Character Recognition (OCR)?
OCR is a long-used machine vision technology that enables machines to recognise numeric and text characters from images. An optical character recognition (OCR) system reads the alphanumeric characters, while optical character verification (OCV) systems confirm the presence of a character string.
History of OCR
In the latter half of the 20th Century, the world ran on printed alphanumeric text and data entry. Cheques, invoices, credit card imprinters, and serial numbers followed everywhere money went, and this began to highlight a need for automated text recognition. So, in 1968, the American Type Founders designed OCR-A, one of the first OCR typefaces to be approved by the U.S. Bureau of Standards.

The OCR-A and OCR-B typefaces. The credit card number on the left is classic example of OCR-A.
Each character was designed to be unique enough for a machine to recognise easily; however, it is slightly difficult for humans to read. With this in mind, OCR-B was created later in 1968 by Adrian Frutiger. This typeface is a more balanced OCR font, slightly harder for machines to recognise, but easier for people to read.
As it turned out, OCR would be the first big breakthrough application for machine vision in the UK, with the development of ANPR (Automatic Number Plate Recognition) in the late 1970s by the British Police Scientific Development Branch.
Early trial systems were deployed in 1979 and 1980 on the A1 road and at the Dartford Tunnel, and in 1981, the first arrest for a stolen car was made using evidence captured with ANPR. Through the 1990s and 2000s, software developments made the technology cheaper, more reliable, and easier to use, and today we are seeing many criminals brought to justice using the network of ANPR systems spread across many roads in the UK.

Example of a GB licence plate
Setting up an OCR system
OCR requires a machine vision camera and computer (or smart camera) running image processing software. We’ll get into the different software options a little later on in this series, but for now, let’s focus on the context and input for an OCR system. Like all machine vision systems, you will need to input some visual data.
The images you provide will of course depend on the chosen application– you could be dealing with pharmaceutical bottles with printed dates in factory settings, automotive shots taken from a car, perhaps with road signage off in the distance, or even scanned documents with lots of uniform text. These are all settings that could benefit from the ability to automatically read and process alphanumeric data contained within the images. However, there are a few problems that could arise with each of our examples.

Potential use cases for OCR
Considerations for OCR
CIJ errors
Let’s start with the first of our three examples.
Printed on this bottlecap is dynamic information that will vary based on the batch and time that this product was created. It uses a method of printing that many industries make use of, mainly within food and beverage and pharmaceuticals.
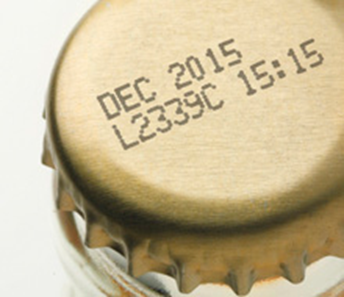
‘CIJ’ or Continuous Inkjet is a non-contact method of industrial printing that produces a continuous flow of ink droplets from a printhead nozzle. These are applied to the surface of a package or label. Using electrostatic deflection, as many as 120,000 droplets can be printed per second.
While this is an extraordinarily efficient method of printing on large quantities, problems such as incorrect line speed, dirty printheads, and non-optimal distances between printhead and printing surface can lead to issues in legibility with CIJ printing. This creates potential issues for label verification, as some printed characters may be legible to human eyes but challenging for vision systems. Conversely, it’s also possible that a vision system will read something that human eyes wouldn’t.
CIJ is very fast and cost-effective, making it an attractive option for industrial settings with lots of units to print onto every day. Unfortunately, they can be prone to printing variations in uniformity, which can make life a little more difficult for OCR software to read.
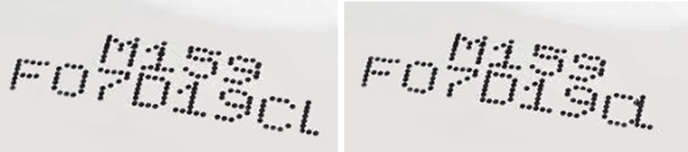
Take this example above. What if the last character, an ‘L’, was printed too close to the neighbouring ‘C’ due to random error? Would the algorithm employed by your chosen OCR software be able to read these characters separately, or would it categorise both as a lower case ‘a’?

A good OCR system will need to recognise the ‘4’ in both instances, despite their differences.
Fonts
Font and typeface are among the most important considerations with OCR. Many typefaces have characters that look very similar to each other, and as mass-printed typefaces need to be cheap, this often means using dot matrix text or other typefaces where all characters end up having high degrees of similarity.
In fact, the reason that Dutch license plates have gaps in some characters is due to higher degrees of recognition accuracy.

License plate example from the Netherlands
Going back to the road sign example, OCR might be being used here inside an autonomous vehicle, so it’s vital to make sure that the algorithm used can handle any font used on road signs. Many different typefaces are used across many different forms of signage out on roadways, so it’s important that the OCR algorithm can perform with 100% accuracy. Some signs use all uppercase characters, some use a mixture of upper and lower case, some are purely numerical whereas others combine alpha and numerical characters.

If we were discussing all of the image processing requirements and considerations for a fully specified machine vision system to be installed into a completely autonomous vehicle, then we’d also be looking at combining OCR with pattern matching to identify the symbols, shapes and colours of road signs, and how deep learning would be perfect for this. What we can look at, however, is the deep learning approach to OCR versus traditional OCR methods.
Traditional OCR vs Deep Learning OCR
Traditional OCR
OCR was one of the first computer vision functions, so it came quite a while before deep learning technology was developed.
Conventional approaches to OCR that rely on traditional machine vision methods have the advantage of being relatively quick to develop. However, they often suffer from slower execution times and lower accuracy compared to deep learning algorithms.
Traditional OCR methods typically involve a series of pre-processing steps to enhance the quality of the document being analysed and remove any noise. This includes cleaning the document and making it noise-free. Subsequently, the document is binarized, converting it into a binary image format, which helps in contour detection. These contours assist in identifying and locating lines and columns within the document.
Deep Learning OCR
Optical character recognition (OCR) is a task that deep learning excels at. For this, your data set would consist of many variations of all possible characters that may come up in practical imaging.
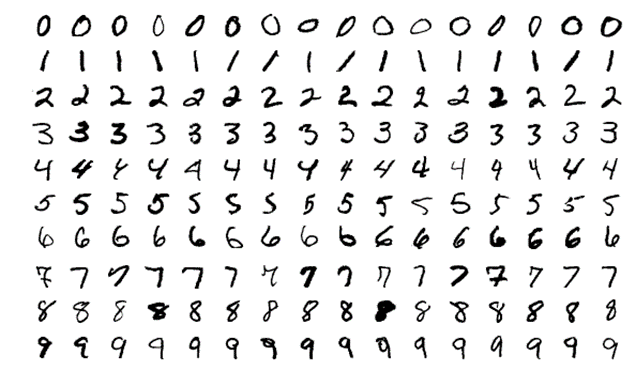
MNIST, pictured above, is a very popular open-source deep learning dataset comprising 70,000 examples of handwritten digits. But what if your application calls for printed typefaces? With DL you need to consider the benefits as well as the limitations when choosing between open source vs. self-gathered data sets. For more on setting up a deep learning system for machine vision, check out our dedicated guide.


