This post will explore Depth Anything V2, a practical solution for robust monocular depth estimation. The Depth Anything model aims to establish a simple yet effective foundation model that performs well with any image in any conditions. To achieve this, the dataset was significantly expanded by using a data engine to gather and automatically annotate around 62 million unlabeled images. This large-scale dataset helps reduce generalization errors.
This powerful model utilizes two key strategies to make data scaling effective. Firstly, it sets a more challenging optimization target using data augmentation tools, pushing the model to learn more robust representations. Secondly, it incorporates auxiliary supervision to assist the model in acquiring rich semantic knowledge from pre-trained encoders. Extensive testing of the model’s zero-shot capabilities on six public datasets and random photos demonstrated impressive generalization abilities.
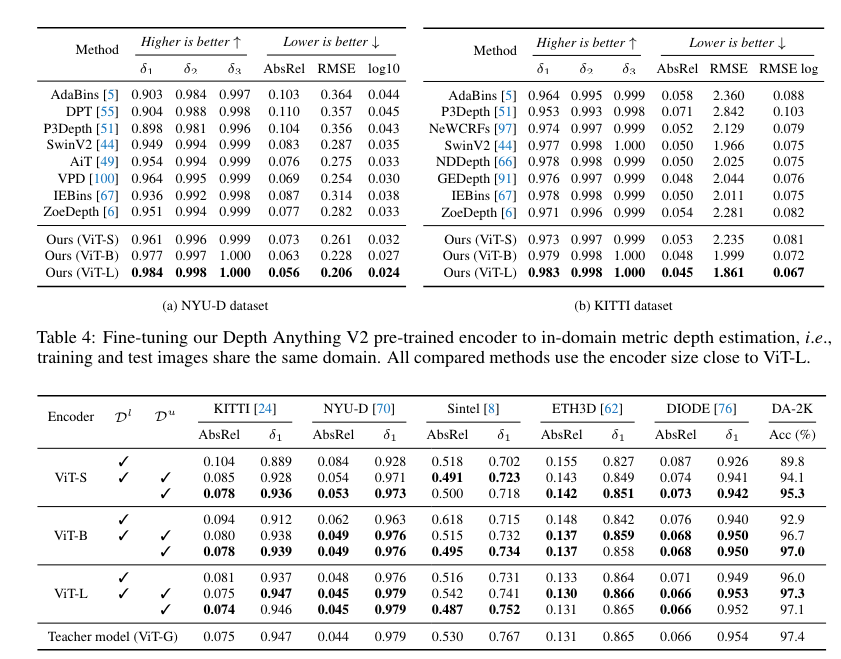
Fine-tuning with metric depth information from NYUv2 and KITTI has also established new state-of-the-art benchmarks. This enhanced depth model has significantly improved depth-conditioned ControlNet.
Related Works on Monocular Depth Estimation (MDE)
Recent advancements in monocular depth estimation have focused on zero-shot relative depth estimation and enhanced modeling techniques such as Stable Diffusion for denoising depth. Projects like MiDaS and Metric3D have amassed millions of labeled images to address dataset scaling challenges. Depth Anything V1 enhanced robustness by leveraging 62 million unlabeled images, highlighting the limitations of labeled real data, and advocating for synthetic data to enhance depth precision. This approach integrates large-scale pseudo-labeled real images and scales up teacher models to address generalization issues stemming from synthetic data. In semi-supervised learning, the emphasis has shifted to real-world applications, seeking to boost performance by incorporating substantial amounts of unlabeled data. Knowledge distillation in this context emphasizes knowledge transfer through prediction-level distillation using unlabeled real images, underscoring the significance of large-scale unlabeled data and larger teacher models for effective knowledge transfer across different model scales.
Strengths of the Model
This research aims to establish a versatile evaluation benchmark for relative monocular depth estimation that can:
1) Provide precise depth relationships
2) Cover extensive scenes
3) Consist mostly of high-resolution images for modern applications.
The research paper also endeavors to build a foundational model for MDE that boasts the following strengths:
- Deliver robust predictions for complex scenes, including intricate layouts, transparent objects like glass, and reflective surfaces such as mirrors and screens.
- Capture fine details in predicted depth maps, comparable to the precision of Marigold, including thin objects like chair legs and small holes.
- Offer a range of model scales and efficient inference capabilities to support various applications.
- Be highly adaptable and suitable for transfer learning, allowing for fine-tuning in downstream tasks. For example, Depth Anything V1 has been the pre-trained model choice for all leading teams in the 3rd MDEC1.
What is Monocular Depth Estimation (MDE)?
Monocular depth estimation is a method used to determine the distances of objects in an image captured by a single camera.

Imagine being able to look at a photo and determine which objects are close and which are far away. Monocular depth estimation employs computer algorithms to automatically accomplish this task. It analyzes visual cues in the image, such as object size and overlap, to estimate their distances.
This technology finds applications in various fields, including autonomous vehicles, virtual reality, and robotics, where understanding object depth is crucial for safe navigation and interaction.
The two primary categories are:
- Absolute depth estimation: A task variant aiming to provide exact depth measurements from the camera in meters or feet. Models for absolute depth estimation produce depth maps with numerical values representing real-world distances.
- Relative depth estimation: Predicts the relative order of objects or points in a scene without specifying exact measurements. These models generate depth maps showing which parts of the scene are closer or farther from each other without detailing distances in meters or feet.
Model Framework
The model pipeline for training Depth Anything V2 includes three major steps:
- Training a teacher model based on DINOv2-G encoder on high-quality synthetic images.
- Generating accurate pseudo-depth on large-scale unlabeled real images.
- Training a final student model on the pseudo-labeled real images for robust generalization.
Here’s a simplified explanation of the training process for Depth Anything V2:
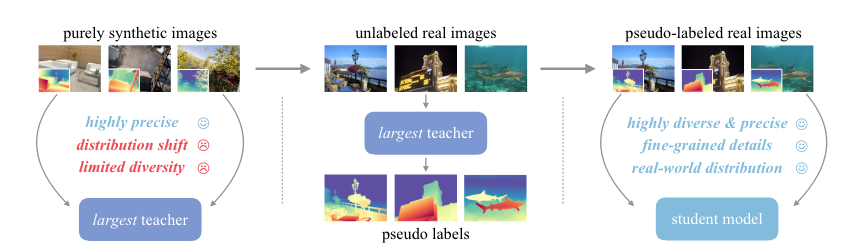
- Model Architecture: Depth Anything V2 utilizes the Dense Prediction Transformer (DPT) as the depth decoder, built on top of DINOv2 encoders.
- Image Processing: All images are resized so their shortest side is 518 pixels, then a random 518×518 crop is taken to standardize the input size for training.
- Training the Teacher Model: The teacher model is initially trained on synthetic images with the following specifications:
- Batch Size: A batch size of 64 is used.
- Iterations: The model is trained for 160,000 iterations.
- Optimizer: The Adam optimizer is employed.
- Learning Rates: The learning rate for the encoder is set to 5e-6, and for the decoder, it’s 5e-5.
- Training on Pseudo-Labeled Real Images: In the third stage, the model is trained on pseudo-labeled real images generated by the teacher model with the following specifications:
- Batch Size: A larger batch size of 192 is used.
- Iterations: The model is trained for 480,000 iterations.
- Optimizer: The same Adam optimizer is used.
- Learning Rates: The learning rates remain the same as in the previous stage.
- Dataset Handling: During both training stages, the datasets are concatenated without balancing, meaning they are combined without adjusting their proportions.
- Loss Function Weights: The weight ratio of the loss functions Lssi (self-supervised loss) and Lgm (ground truth matching loss) is set to 1:2, giving twice the importance to Lgm during training.
This approach ensures the model’s robustness and performance across various image types.
To validate the model’s performance, the Depth Anything V2 model has been compared to Depth Anything V1 and MiDaS V3.1 using five test datasets. The model outperforms MiDaS but slightly lags behind V1.
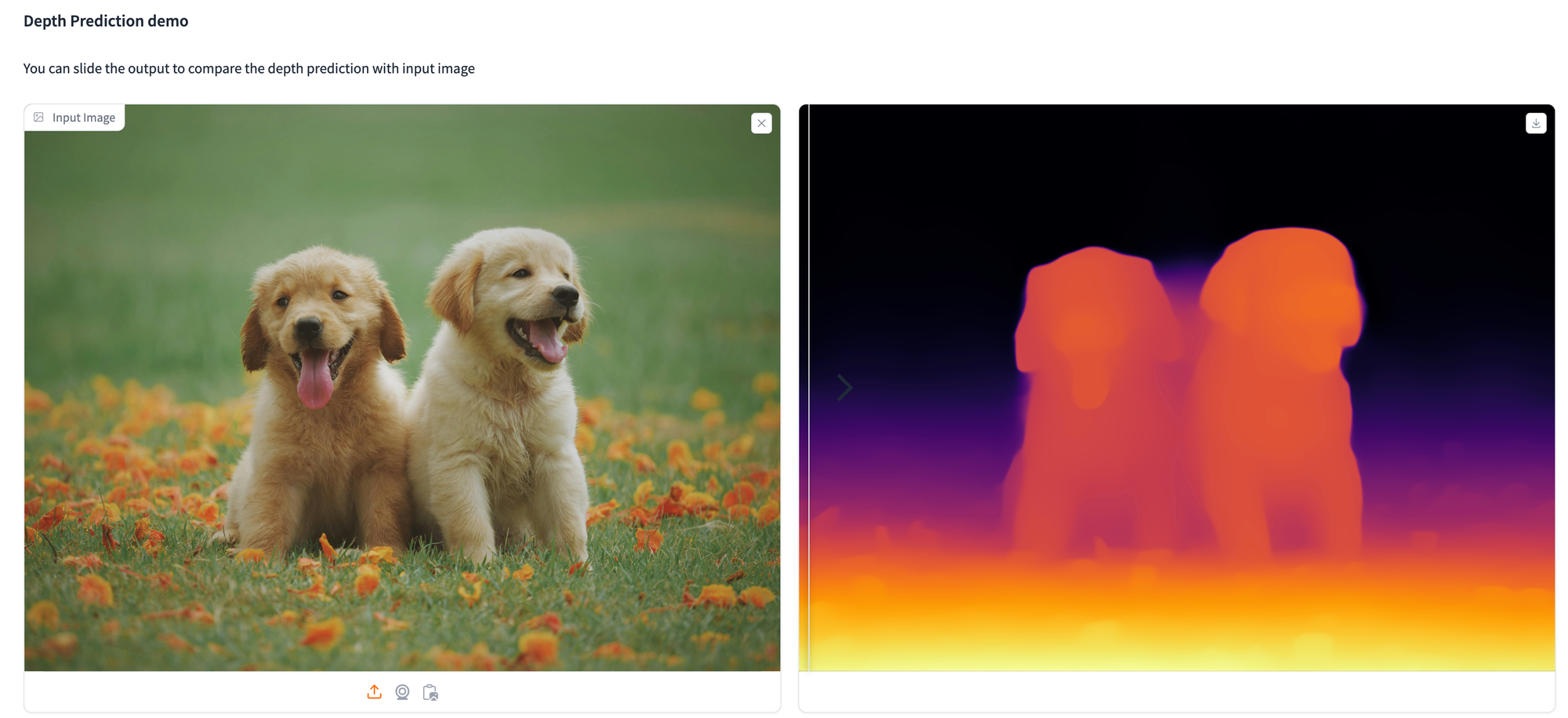
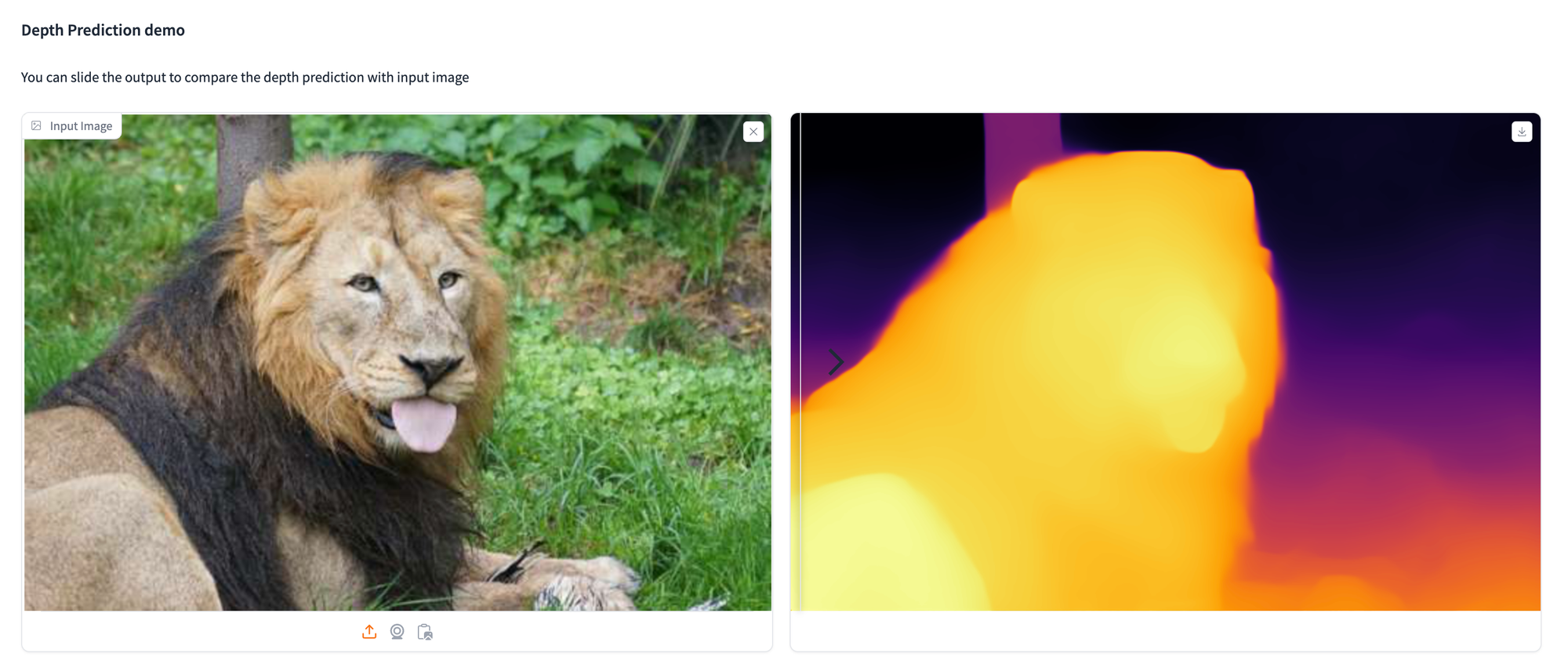
Paperspace Demonstration
Depth Anything offers a practical solution for monocular depth estimation, having been trained on 1.5M labeled and over 62M unlabeled images.
The list below outlines model details for depth estimation and their respective inference times.
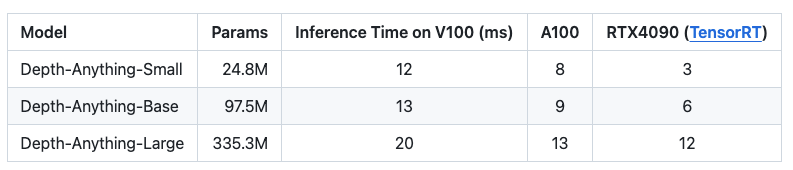
For this demonstration, we recommend utilizing an NVIDIA RTX A4000. The NVIDIA RTX A4000 is a high-performance professional graphics card designed for creators and developers. Featuring the NVIDIA Ampere architecture, it includes 16GB of GDDR6 memory, 6144 CUDA cores, 192 third-generation tensor Cores, and 48 RT cores. The RTX A4000 excels in demanding workflows like 3D rendering, AI, and data visualization, making it ideal for architecture, media, and scientific research professionals.
Paperspace also provides robust H100 GPUs. To maximize the potential of Depth Anything and your Virtual Machine, we recommend replicating this setup on a Paperspace by DigitalOcean Core H100 Machine.
Bring this project to life
Run the code below to check the GPU
!nvidia-smi
Next, clone the repo and import the necessary libraries.
from PIL import Image
import requests!git clone https://github.com/LiheYoung/Depth-Anythingcd Depth-AnythingInstall the requirements.txt file.
!pip install -r requirements.txt!python run.py --encoder vitl --img-path /notebooks/Image/image.png --outdir depth_visArguments:
--img-path: 1) specify a directory containing all the desired images, 2) specify a single image, or 3) specify a text file listing all the image paths.- Setting
--pred-onlysaves only the predicted depth map. Without this option, the default behavior is to visualize the image and depth map side by side. - Setting
--grayscalesaves the depth map in grayscale. By default, a color palette is applied to the depth map.
If you want to use Depth Anything on videos:
!python run_video.py --encoder vitl --video-path assets/examples_video --outdir video_depth_visRun the Gradio Demo:-
To run the gradio demo locally:-
!python app.pyIf you encounter KeyError: ‘depth_anything’, please install the latest transformers from source:
!pip install git+https://github.com/huggingface/transformers.gitBelow are examples showcasing the utilization of the depth estimation model to analyze various images.