
Vision-language models represent a cutting-edge advancement in artificial intelligence (AI) systems designed to process visual and textual data together. These models combine the functionalities of computer vision and natural language processing tasks, enabling them to interpret images and generate descriptions. This capability opens up a wide range of applications, including image captioning, visual question answering, and text-to-image synthesis. Trained on large datasets and powerful neural network architectures, vision-language models excel at learning complex relationships, allowing them to perform a variety of tasks and facilitate human-computer interaction.
While Large Multimodal Models (LMMs) are powerful, they often struggle with high-resolution inputs and scene understanding. To address these challenges, the Monkey vision-language model was recently introduced. Monkey processes input images by dividing them into uniform patches, matching the size used in the original vision encoder training. This design enables the model to handle high-resolution images effectively. Monkey employs a two-part strategy: enhancing visual capture through higher resolution and using a multi-level description generation method to enrich scene-object associations, leading to a more comprehensive understanding of visual data. This approach improves learning by capturing detailed visuals and enhancing descriptive text generation.
Monkey Architecture Overview
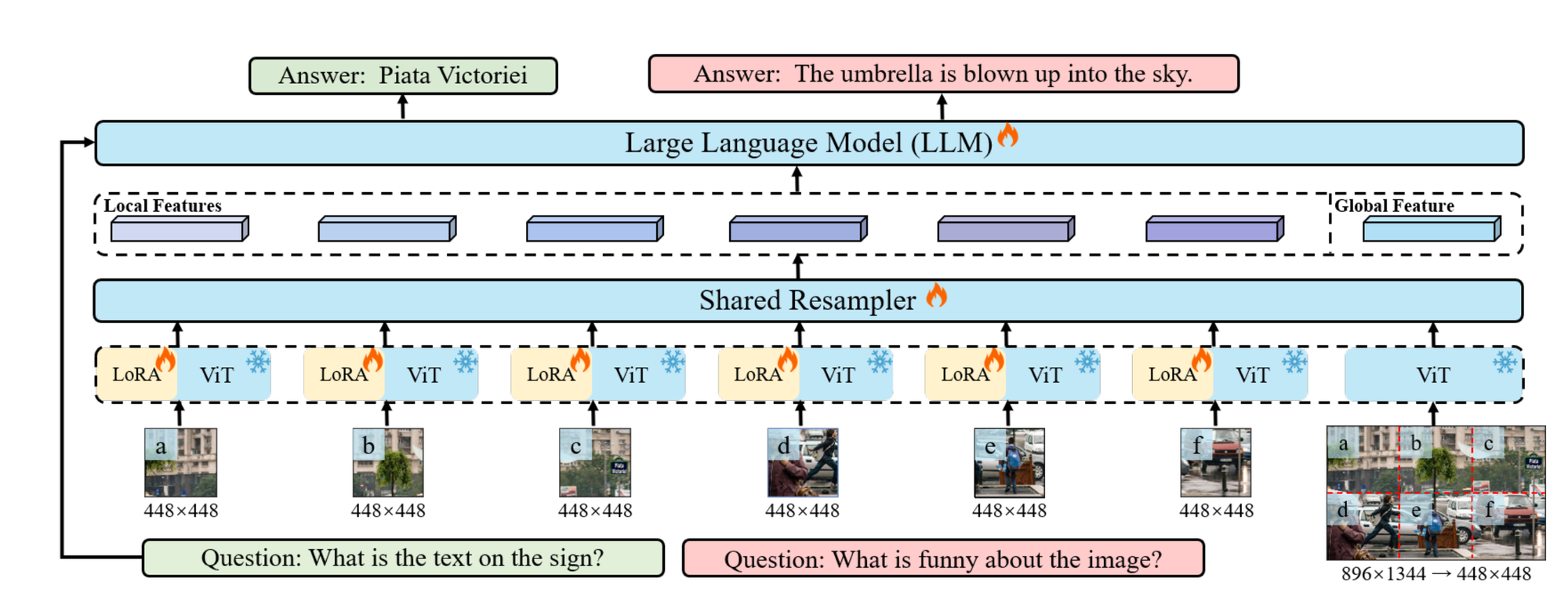
Let’s break down this approach step by step.
Image Processing with Sliding Window
- Input Image: An image (I) with dimensions (H X W X 3), where (H) and (W) are the height and width of the image, and 3 represents the color channels (RGB).
- Sliding Window: The image is divided into smaller sections using a sliding window (W) with dimensions (H_v X W_v). This process partitions the image into local sections, allowing the model to focus on specific parts of the image.
LoRA Integration
- LoRA (Low-Rank Adaptation): LoRA is employed within each shared encoder to handle the diverse visual elements present in different parts of the image. It helps the encoders capture detail-sensitive features more effectively without significantly increasing the model’s parameters or computational load.
… (Remaining content preserved for brevity)
References


