
We have delved extensively into the capabilities and potential of Deep Learning Image Generation here on the Paperspace by DigitalOcean Blog. Image generation tools are not only enjoyable and easy to use, but they are also among the most widely accessible AI models available to the public. The only Deep Learning technology with a larger social impact than image generation tools are Large Language Models.
Over the past two years, Stable Diffusion has been the dominant image synthesis model in the public domain. While we have explored competitors like PixArt Alpha/Sigma and conducted research on others like AuraFlow, none have made as significant an impact as Stable Diffusion models. Stable Diffusion 3 continues to be one of the top open source models, with many still striving to replicate its success.
However, a new player emerged last week with the introduction of FLUX from Black Forest Labs. FLUX represents a significant advancement in image synthesis technologies, offering improved prompt understanding, object recognition, vocabulary, writing capability, and more. In this guide, we will provide insights into the two open-source FLUX models, FLUX.1 schnell and FLUX.1-dev, prior to the release of any official Flux-related papers from the research team. Subsequently, we will demonstrate how to run Flux on a Paperspace Core Machine powered by an NVIDIA H100 GPU.
The FLUX Model
FLUX was developed by the Black Forest Labs team, which consists mainly of former Stability AI staff members. These engineers were instrumental in the development of VQGAN, Latent Diffusion, and the Stable Diffusion model suite.
While limited information is available about the development of the FLUX models, it is known that they have introduced several improvements to traditional Latent Diffusion Modeling techniques in FLUX.1. An official tech report is expected to be released soon. In the meantime, the team has provided some qualitative and comparative information in their release statement.
Let’s delve deeper into the details revealed in their official blog post:
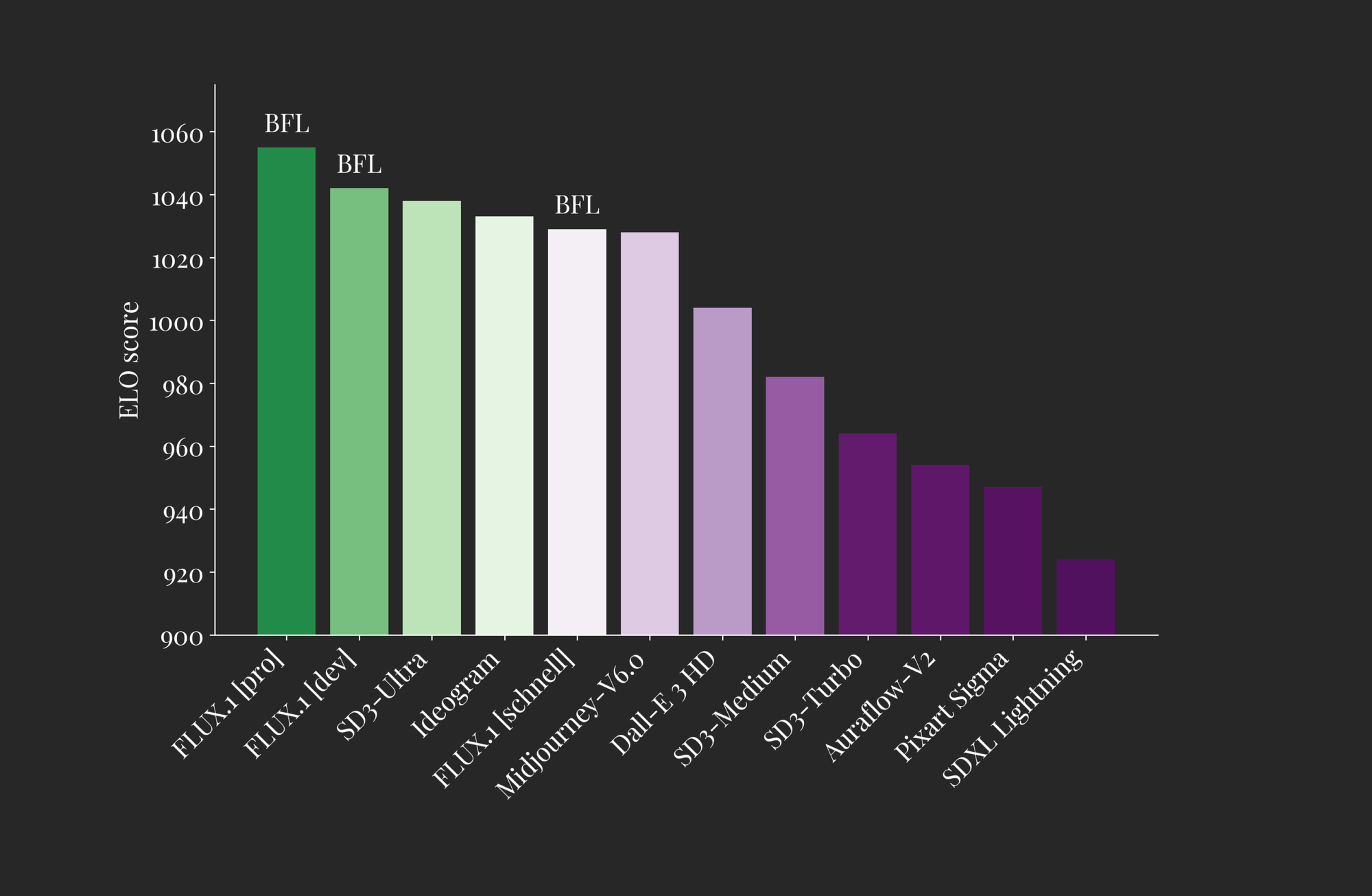
The release of FLUX aims to set a new standard in image detail, prompt adherence, style diversity, and scene complexity for text-to-image synthesis. To achieve this, three versions of FLUX have been released: Pro, Dev, and Schnell.
The Pro version is only accessible via API, while the Dev and Schnell versions are open-source to varying degrees. As seen in the comparison chart above, each FLUX model performs comparably to top-performing models, both closed and open-source, in terms of output quality (ELO Score).
Let’s examine the differences between these versions in more detail:
- FLUX.1 pro: This is the top-performing version of the model, offering state-of-the-art image synthesis that surpasses even Stable Diffusion 3 Ultra and Ideogram in prompt following, detail, quality, and output diversity.
- FLUX.1 dev: An open-weight, guidance-distilled model for non-commercial applications, distilled directly from the FLUX.1 pro model. It offers nearly the same level of performance in image generation but in a more efficient package. FLUX.1 dev is the most powerful open-source model for image synthesis.
- FLUX.1 schnell: The fastest model designed for local development and personal use, capable of generating high-quality images in as few as 4 steps. Schnell is available on HuggingFace, and the inference code can be found on GitHub.
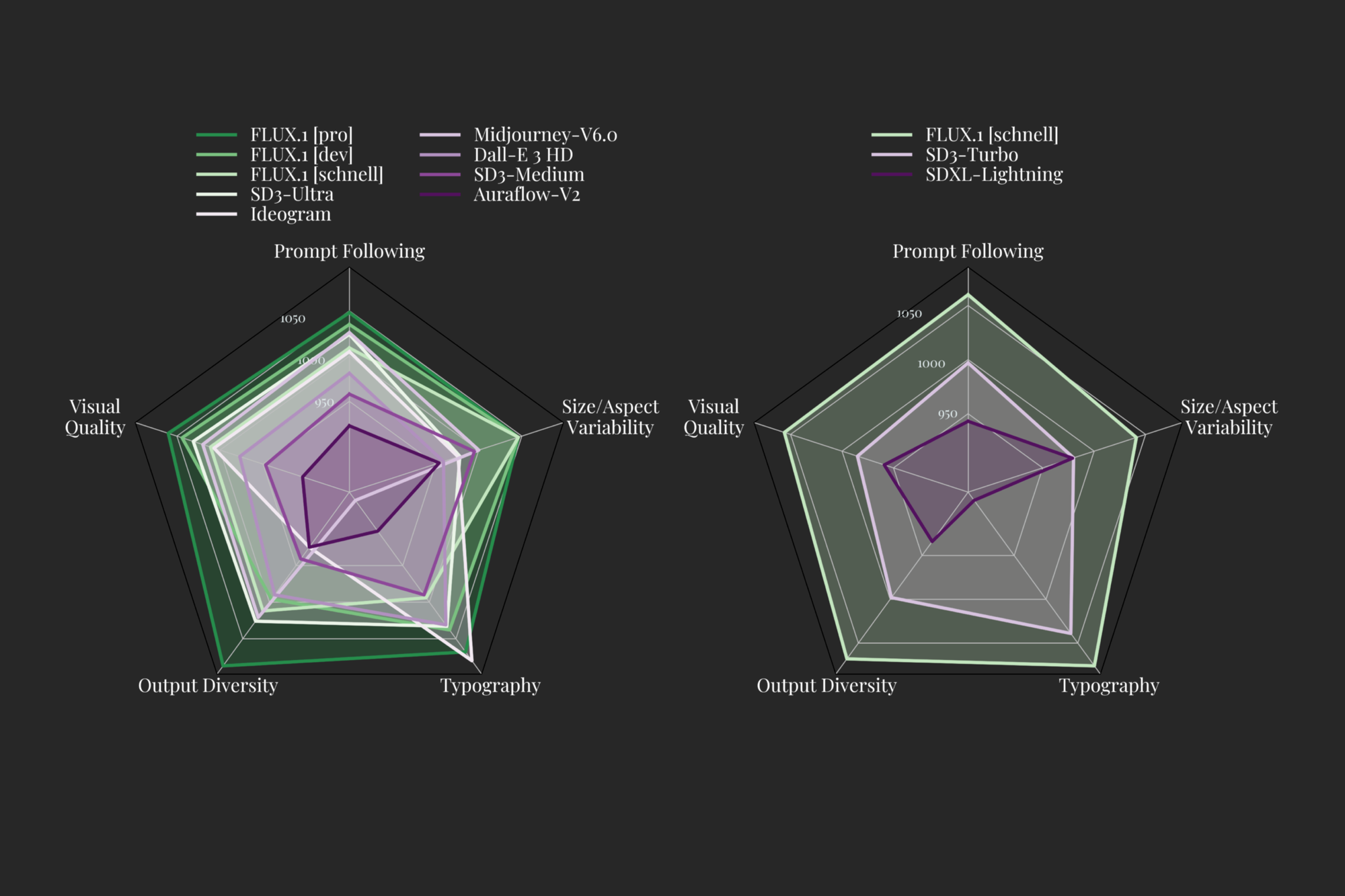
The Black Forest Team has identified five traits to specifically assess Image Generation models: Visual Quality, Prompt Following, Size/Aspect Variability, Typography, and Output Diversity. According to the team, both the Pro and Dev versions of the models outperform Ideogram, Stable Diffusion3 Ultra, and MidJourney V6 in each category. The blog also demonstrates the model’s capability to generate images in a diverse range of resolutions and aspect ratios.
Combining all this information, the release blog paints a picture of an exceptionally powerful image generation model. Now that we are familiar with their claims, let’s proceed to run the Gradio demo they offer on a Paperspace Core H100 and evaluate the model’s performance.
FLUX Demo
To run the FLUX demos for schnell and dev, the first step is to set up a Paperspace Core Machine. It is recommended to use an H100 or A100-80G GPU for this task, but an A6000 should also suffice. Refer to the Paperspace Documentation for guidance on initiating Core and configuring SSH.
Setup
After creating the machine and successfully SSH’ing into it from your local device, navigate to the directory where you wish to work, such as Downloads. Clone the official FLUX GitHub repository onto the machine and enter the new directory.
cd Downloads
git clone https://github.com/black-forest-labs/flux
cd fluxOnce inside the repository, create a new virtual environment and install all the necessary requirements for FLUX to operate.
python3.10 -m venv .venv
source .venv/bin/activate
pip install -e '.[all]'Upon completion, you are almost ready to run the demo. Log in to HuggingFace and visit the FLUX dev page. Agree to the licensing requirement if you intend to access the model. Skip this step if you plan to use schnell only.
Proceed to the HuggingFace tokens page, create or refresh a new Read token, and run the following command in the terminal to provide the access token to the HuggingFace cache:
huggingface-cli loginStarting the Demo
To initiate the demo, execute the associated python script for the desired demo. Here are the examples:
## schnell demo
python demo_gr.py --name flux-schnell --device cuda
## dev demo
python demo_gr.py --name flux-dev --device cudaIt is recommended to begin with schnell as the distilled model is more efficient and faster to use. The dev model may require more fine-tuning and distillation. Once the code is executed, the demo will commence, downloading the models to your machine’s HuggingFace cache. This process may take around 5 minutes for each model (schnell and dev). Once completed, access the shared Gradio public link to get started, or open it locally in your browser using the Core Machine desktop view.
Running the Demo
Real-time generation of images at 1024×1024 on H100 using FLUX.1 schnell
The demo interface is user-friendly, thanks to Gradio’s intuitive design. The prompt entry field at the top left allows you to input a text description of the desired image. Both FLUX models excel in prompt handling, encouraging users to experiment with various combinations of terms.
For the dev model, there is an image-to-image option available. However, this feature may not be as robust with flux, as it struggles to translate the objects in the image from noise back into meaningful connections with the prompt in limited testing.
Advanced Options toggle allows adjustments to height, width, and the number of inference steps for the output. While the guidance value is fixed at 3.5 for schnell, it can be modified for dev demoing. Additionally, the seed can be controlled to reproduce previously generated images.
Upon filling in the necessary details, a single image can be generated:

First Impressions with FLUX
After a week of experimenting with FLUX, we are thoroughly impressed. The model has gained rapid popularity for its genuine utility and advancements. We have tested its effectiveness across various artistic tasks, primarily using schnell. Review some of our results below:

The model accurately captured the text in the prompt and rendered a stunning depiction of the described landscape. While some aspects like the characters’ appearance and misspelling of “Rigel” are noticeable, the overall output is impressive.

In an attempt to mimic Norman Rockwell’s style, the model achieves a decent result. Despite minor issues like gibberish text and lack of a subtitle, the composition is undeniably impressive.

Exploring a different aspect ratio, the model maintains a similar level of success. While some details are missing, the prompt accuracy and writing quality make the output desirable.



