
YOLO (You Only Look Once) is a cutting-edge object-detection algorithm first introduced as a research paper by J. Redmon, et al. (2015). In the realm of real-time object identification, YOLOv11 architecture represents a significant advancement over its predecessor, the Region-based Convolutional Neural Network (R-CNN).
Utilizing an entire image as input, this single-pass approach with a single neural network predicts bounding boxes and class probabilities. In this post, we will delve into YOLOv11 – the most recent iteration developed by Ultralytics.
About us: Viso Suite is an End-to-End Computer Vision Infrastructure that offers all the necessary tools to train, build, deploy, and manage computer vision applications at scale. By combining accuracy, reliability, and lower total cost of ownership, Viso Suite is ideal for multi-use case, multi-location deployments. To explore enterprise-grade computer vision infrastructure, schedule a demo of Viso Suite with our team of experts.
What is YOLOv11?
YOLOv11 is the latest iteration of YOLO, an advanced real-time object detection system. The YOLO family enters a new era with YOLOv11, a more capable and adaptable model that pushes the boundaries of computer vision.
The model supports various computer vision tasks such as pose estimation and instance segmentation. The computer vision community that has utilized previous YOLO versions will appreciate YOLOv11 for its improved efficiency and optimized architecture.
Glenn Jocher, CEO, and founder of Ultralytics, stated: “With YOLOv11, we aimed to create a model that combines power and practicality for real-world applications. Its enhanced accuracy and efficiency make it a versatile tool tailored to address specific challenges across different sectors.”
Supported Tasks
Ultralytics’ YOLOv11 is a widely used tool among developers and researchers due to its innovative architecture. The computer vision community can leverage YOLOv11 to create innovative solutions and advanced models. It enables a variety of computer vision tasks, including:
- Object Detection
- Instance Segmentation
- Pose Estimation
- Oriented Detection
- Classification
Some of the key enhancements include improved feature extraction, more accurate detail capture, higher accuracy with fewer parameters, and faster processing rates that significantly enhance real-time performance.
An Overview of YOLO Models
Here is a summary of the YOLO family of models up to YOLOv11.
| Release | Authors | Tasks | Paper | |
|---|---|---|---|---|
| YOLO | 2015 | Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi | Object Detection, Basic Classification | You Only Look Once: Unified, Real-Time Object Detection |
| YOLOv2 | 2016 | Joseph Redmon, Ali Farhadi | Object Detection, Improved Classification | YOLO9000: Better, Faster, Stronger |
| YOLOv3 | 2018 | Joseph Redmon, Ali Farhadi | Object Detection, Multi-scale Detection | YOLOv3: An Incremental Improvement |
| YOLOv4 | 2020 | Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao | Object Detection, Basic Object Tracking | YOLOv4: Optimal Speed and Accuracy of Object Detection |
| YOLOv5 | 2020 | Ultralytics | Object Detection, Basic Instance Segmentation (via custom modifications) | no |
| YOLOv6 | 2022 | Chuyi Li, et al. | Object Detection, Instance Segmentation | YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications |
| YOLOv7 | 2022 | Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao | Object Detection, Object Tracking, Instance Segmentation | YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors |
| YOLOv8 | 2023 | Ultralytics | Object Detection, Instance Segmentation, Panoptic Segmentation, Keypoint Estimation | no |
| YOLOv9 | 2024 | Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao | Object Detection, Instance Segmentation | YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information |
| YOLOv10 | 2024 | Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding | Object Detection | YOLOv10: Real-Time End-to-End Object Detection |
Key Advantages of YOLOv11
YOLOv11 represents an improvement over YOLOv9 and YOLOv10, both released earlier in 2024. It features enhanced architectural designs, more effective feature extraction algorithms, and improved training methods. The unique combination of YOLOv11’s speed, accuracy, and efficiency sets it apart as one of Ultralytics’ most powerful models to date.
YOLOv11 boasts an improved design that enables more precise detection of intricate details – even in challenging scenarios. It also offers enhanced feature extraction, allowing for the extraction of multiple patterns and details from images.
Compared to its predecessors, Ultralytics’ YOLOv11 introduces several significant improvements. Key advancements include:
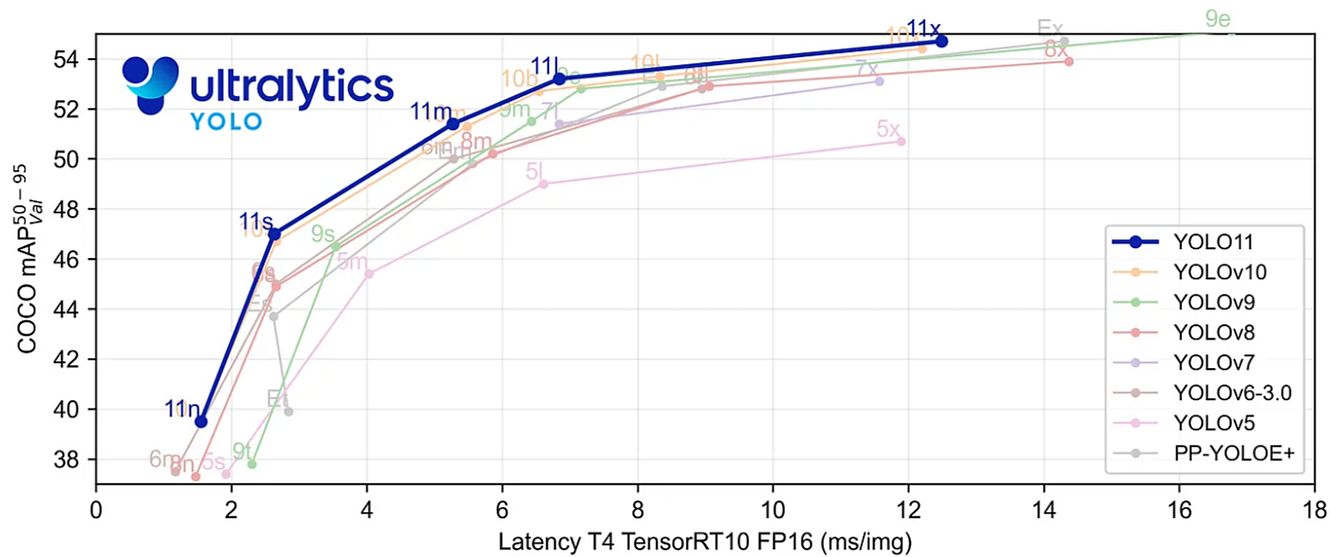
- Better accuracy with fewer parameters: YOLOv11m is more computationally efficient without sacrificing accuracy. It achieves greater mean Average Precision (mAP) on the COCO dataset with 22% fewer parameters than YOLOv8m.
- Wide variety of tasks supported: YOLOv11 is capable of performing a wide range of CV tasks, including pose estimation, object recognition, image classification, instance segmentation, and orientated object detection (OBB).
- Improved speed and efficiency: Faster processing rates are achieved via improved architectural designs and training pipelines that strike a compromise between accuracy and performance.
- Fewer parameters: fewer parameters make models faster without significantly affecting v11’s correctness.
- Improved feature extraction: YOLOv11 has a better neck and backbone architecture to improve feature extraction capabilities, which leads to more accurate object detection.
- Adaptability across contexts: YOLOv11 is adaptable to a wide range of contexts, such as cloud platforms, edge devices, and systems that are compatible with NVIDIA GPUs.
YOLOv11 – How to Use It?
As of October 10, 2024, Ultralytics has not yet published the YOLOv11 paper or its architecture diagram. However, there is sufficient documentation available on GitHub. The model is less resource-intensive and capable of handling complex tasks. It is an excellent choice for challenging AI projects as it enhances large-scale model performance.
The training process has improvements to the augmentation pipeline, making it easier for YOLOv11 to adapt to various tasks – whether small projects or large-scale applications. To start using YOLOv11, install the latest version of the Ultralytics package:
pip install ultralytics>=8.3.0
You can utilize YOLOv11 for real-time object detection and other computer vision applications with just a few lines of code. Use this code to load a pre-trained YOLOv11 model and perform inference on an image:
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Run inference on an image
results = model("path/to/image.jpg")
# Display results
results[0].show()
 Post navigation
Post navigation


