
Machine Learning (ML) is a subset of artificial intelligence (AI) that focuses on developing algorithms to learn from data and make predictions or decisions without requiring detailed programming for each task. Instead of following strict rules, ML models identify patterns and improve their effectiveness over time.
Understanding these concepts and the associated algorithms is essential for effectively using machine learning in various fields, ranging from healthcare and finance to automation and artificial intelligence applications.
In this post, we will delve into different types of Machine Learning algorithms, how they operate, and their real-world applications to enhance your understanding of their significance and practical implementation.
What is a Machine Learning Algorithm?
A machine learning algorithm comprises rules or mathematical models that enable computers to identify patterns in data and make predictions or decisions without explicit programming. These algorithms analyze input data, identify relationships, and improve efficiency with time.
How They Work:
- Train on a dataset to identify patterns.
- Test on new data to assess performance.
- Optimize by adjusting parameters to enhance accuracy.
Machine learning algorithms power applications such as recommendation systems, fraud detection, and autonomous vehicles.
Types of Machine Learning Algorithms
Machine Learning algorithms can be classified into five types:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
- Semi-Supervised Learning
- Deep Learning Algorithms
1. Supervised Learning
In supervised learning, the model is trained using a labeled dataset, where each training example contains an input-output pair. This algorithm learns to associate inputs with the correct outputs based on historical data.
Common Supervised Learning Algorithms:
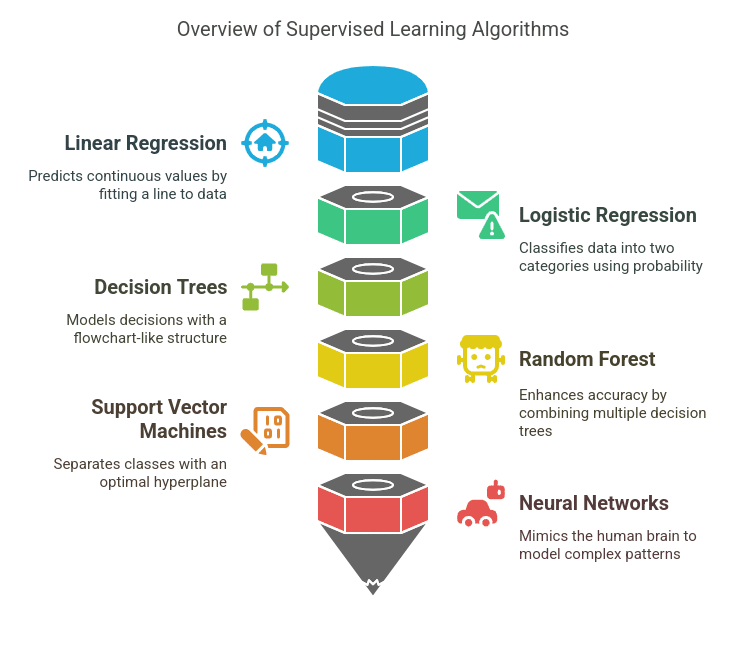
A. Linear Regression
Linear Regression is a fundamental algorithm used to predict continuous numerical values based on input features. It fits a straight line (y=mx+b) to the data that best represents the relationship between the independent and dependent variables.
- Example: Estimating home values based on factors like area, bedroom count, and location.
- Key Concept: It minimizes the difference between observed and predicted values using the least squares method.
B. Logistic Regression
Logistic Regression is used for classification, not regression, despite its name. It uses the sigmoid function to map predicted values to a range of 0 to 1, making it suitable for binary classification problems.
- Example: Identifying if an email is spam based on specific keywords.
- Key Concept: It uses probabilities to categorize data points into two groups and applies a threshold (e.g., 0.5) for decision-making.
C. Decision Trees
Decision Trees are models that resemble flowcharts, with each node representing a feature, each branch indicating a decision, and each leaf denoting an outcome. They can handle both classification and regression tasks.
- Example: A bank deciding whether to approve a loan based on income, credit score, and work history.
- Key Concept: It splits data based on feature conditions to maximize information gain using metrics like Gini Impurity or Entropy.
D. Random Forest
Random Forest is an ensemble learning technique that creates multiple decision trees and combines their results to improve accuracy and reduce overfitting.
- Example: Predicting customer churn based on transaction history, demographics, and customer service interactions.
- Key Concept: It uses bootstrap aggregating (bagging) to generate diverse trees and averages their predictions for stability.
E. Support Vector Machines (SVM)
SVM is a robust classification algorithm that identifies the optimal hyperplane to separate different classes. It is particularly useful for datasets with clear margins between categories.
- Example: Classifying handwritten digits in the MNIST dataset.
- Key Concept: It uses kernel functions (linear, polynomial, RBF) to map data into higher dimensions for better separation.
F. Neural Networks
Neural Networks simulate the human brain, consisting of multiple layers of interconnected neurons that learn from data. They are extensively used for deep learning applications.
- Example: Image recognition in self-driving cars to detect pedestrians, traffic signs, and other vehicles.
Applications of Supervised Learning:
- Email Spam Filtering
- Medical Diagnosis
- Customer Churn Prediction
2. Unsupervised Learning
Unsupervised learning deals with data that lacks labeled responses. The algorithm uncovers hidden patterns and structures in the dataset.
Common Unsupervised Learning Algorithms:
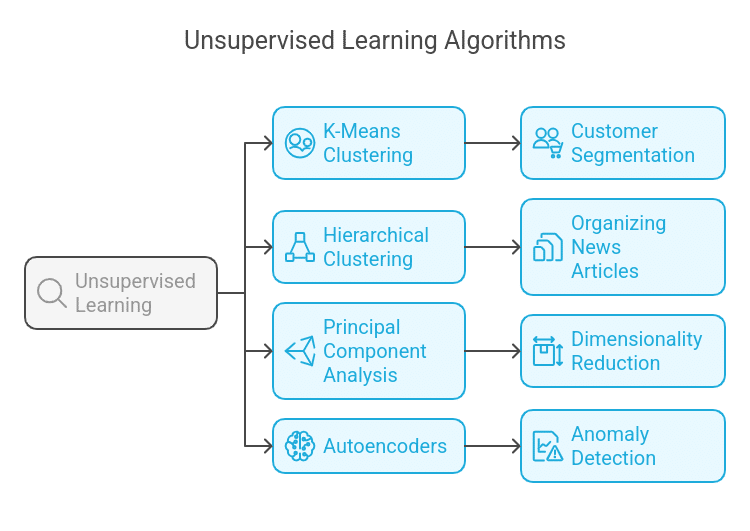
A. K-Means Clustering
K-Means is a popular clustering algorithm that groups similar data points into K clusters. It assigns each point to the nearest cluster centroid and updates centroids iteratively to minimize variance within clusters.
- Example: Segmenting customers in e-commerce based on their buying behavior.
- Key Concept: It uses the Euclidean distance to assign data points to clusters and updates centroids until convergence.
B. Hierarchical Clustering
Hierarchical Clustering constructs a cluster hierarchy using either Agglomerative (bottom-up) or Divisive (top-down) methods. It generates a dendrogram to visualize relationships between clusters.
- Example: Categorizing news articles into topic-based groups without predefined categories.
- Key Concept: It uses distance metrics (e.g., single-linkage, complete-linkage) to merge or split clusters.
C. Principal Component Analysis (PCA)
PCA is a technique for reducing dimensionality that transforms high-dimensional data into a lower-dimensional space while preserving essential information. It identifies the principal components, which are the directions of maximum variance.
- Example: Reducing the number of features in an image dataset while retaining critical patterns for machine learning models.
- Key Concept: It uses eigenvectors and eigenvalues to project data onto fewer dimensions while minimizing information loss.
D. Autoencoders
Autoencoders are a type of neural network used for feature learning, compression, and anomaly detection. They consist of an encoder (compressing input data) and a decoder (reconstructing the original data).
- Example: Detecting fraudulent transactions by identifying unusual patterns in financial data.
- Key Concept: It uses a bottleneck layer to capture important features and reconstructs data using mean squared error (MSE) loss.
Applications of Unsupervised Learning:
- Customer Segmentation
- Anomaly Detection in Fraud Detection
- Recommender Systems (e.g., Netflix, Amazon)
Learn about the key differences between Supervised and Unsupervised Learning and their impact on machine learning models.
3. Reinforcement Learning
Reinforcement learning (RL) involves an agent learning to interact with an environment to maximize the total sum of rewards over time.
Key Concepts in Reinforcement Learning:
- Agent – The entity that takes actions.
- Environment – The world in which the agent operates.
- Actions – Choices the agent can make.
- Rewards – Feedback signals guiding the agent.
Common Reinforcement Learning Algorithms:
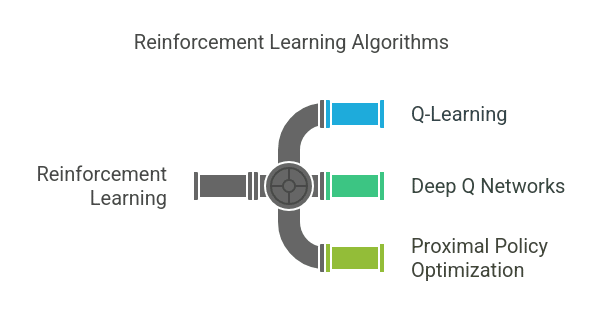
A. Q-Learning
Q-learning is a reinforcement learning algorithm without a model that develops an optimal action-selection policy through a Q-table. It follows the Bellman equation to update the Q-values based on rewards received from the environment.
- Example: Training an AI agent to play a simple game like Tic-Tac-Toe by learning which moves lead to victory over time.
- Key Concept: It uses the ε-greedy policy to balance exploration (trying new actions) and exploitation (choosing the best-known action).
B. Deep Q Networks (DQN)
DQN is an extension of Q-Learning that utilizes deep neural networks to estimate the Q-values, making it suitable for high-dimensional environments where maintaining a Q-table is impractical.
- Example: Teaching an AI to play Atari games, like Breakout, where raw pixel data is used as input.
- Key Concept: It uses experience replay (storing past experiences) and a target network (stabilizing training) to enhance learning.
C. Proximal Policy Optimization (PPO)
PPO is a policy-based reinforcement learning algorithm that optimizes actions using a trust region approach, ensuring stable updates and preventing large, disruptive policy changes.
- Example: Training robotic arms to grasp objects efficiently or enabling game AI to strategize in complex environments.
- Key Concept: It uses clipped objective functions to prevent overly aggressive updates and enhance training stability.
Applications of Reinforcement Learning:
- Game Playing (e.g., AlphaGo, OpenAI Gym)
- Robotics Automation
- Autonomous Vehicles
Understand the basics of Reinforcement Learning and use it to make decisions in AI and robotics.
4. Semi-Supervised Learning
Semi-supervised learning falls between supervised and unsupervised learning, where only a small portion of the dataset is labeled, and the rest is unlabeled.
Applications:
- Speech Recognition
- Text Classification
- Medical Image Analysis
5. Deep Learning Algorithms
Deep Learning is a branch of Machine Learning that incorporates neural networks with multiple layers (i.e., deep networks) to discover complex features of raw data.
Popular Deep Learning Architectures:
Applications:
Master Machine Learning with Python in this free course. Learn key ML concepts, algorithms, and hands-on implementation from industry experts.
Choosing the Right Machine Learning Algorithm
Selecting the appropriate machine learning algorithm depends on various factors, including the nature of the data, the problem type, and computational efficiency.
Here are key considerations for choosing the correct algorithm:
- Type of Data: Structured and Unstructured
- Problem Type: Classification, Regression, Clustering, or Anomaly Detection
- Accuracy vs. Interpretability: Decision trees are easy to interpret, whereas deep learning models are more accurate but more complex to understand.
- Computational Power: Some models require high computational resources (e.g., deep learning).
Experimentation and model evaluation using techniques like cross-validation and hyperparameter tuning are crucial in selecting the best-performing algorithm.
Discover the latest Artificial Intelligence and Machine Learning Trends shaping the future of AI.
Sample Codes of ML Algorithms in Python
Linear Regression in Python
from sklearn.linear_model import LinearRegression
import numpy as np
# Sample Data
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 6, 8, 10])
# Model Training
model = LinearRegression()
model.fit(X, y)
# Prediction
print(model.predict([[6]])) # Output: Approx 12
Logistic Regression in Python
from sklearn.linear_model import LogisticRegression
import numpy as np
# Sample Data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 0, 1, 1, 1]) # Binary classification
# Model Training
model = LogisticRegression()
model.fit(X, y)
# Prediction
print(model.predict([[2.5]])) # Output: 0 or 1 based on learned pattern
K-Means Clustering in Python
from sklearn.cluster import KMeans
import numpy as np
# Sample Data
X = np.array([[1, 2], [2, 3], [3, 4], [8, 9], [9, 10])


