
Imagine the scenario of training a model on raw data without any cleaning, transforming, or optimization. The outcome would be poor predictions, wasted resources, and suboptimal performance. This is where feature engineering comes into play, as it involves extracting the most relevant insights from data to ensure that machine learning models function efficiently.
Whether dealing with structured data, text, or images, mastering feature engineering can be a game-changer. This guide covers effective techniques and best practices to help build high-performance models.
What is Feature Engineering?
Feature engineering is the process of converting raw data into useful input variables (features) that enhance the performance of machine learning models. It helps in selecting the most valuable features to improve a model’s ability to learn patterns and make accurate predictions.
Feature engineering includes methods like feature scaling, encoding categorical variables, feature selection, and building interaction terms.
Why is Feature Engineering Important?
Feature engineering is one of the crucial steps in machine learning. Even the most advanced algorithms can fail if trained on poorly designed features. Here are the reasons why feature engineering matters:
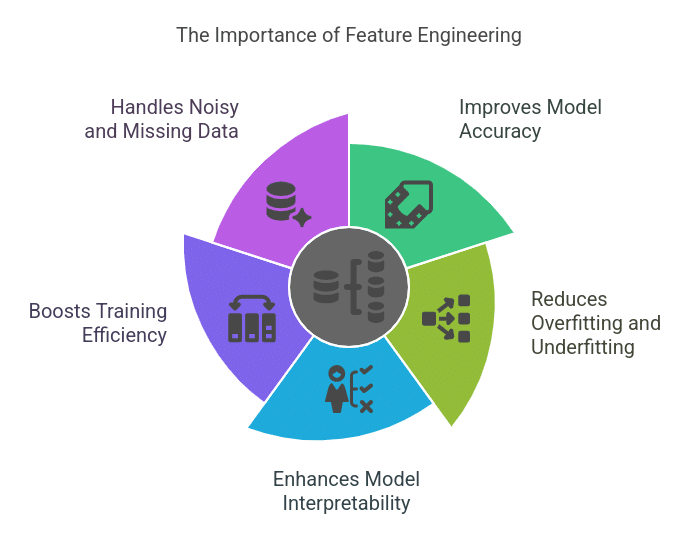
1. Improves Model Accuracy
A well-crafted feature set enables a model to capture patterns more effectively, leading to higher accuracy. For instance, transforming a date column into “day of the week” or “holiday vs. non-holiday” can enhance sales forecasting models.
2. Reduces Overfitting and Underfitting
By eliminating irrelevant or highly correlated features, feature engineering prevents the model from memorizing noise (overfitting) and ensures it generalizes well on unseen data.
3. Enhances Model Interpretability
Features aligned with domain knowledge make the model’s decisions more explainable. For instance, in fraud detection, a feature like “number of transactions per hour” is more informative than raw timestamps.
4. Boosts Training Efficiency
Reducing unnecessary features decreases computational complexity, making training faster and more efficient.
5. Handles Noisy and Missing Data
Raw data often contains incomplete or outlier values. Feature engineering helps clean and structure this data, ensuring better learning outcomes.
Also Read: What is Predictive Modeling?
Key Methods of Feature Engineering
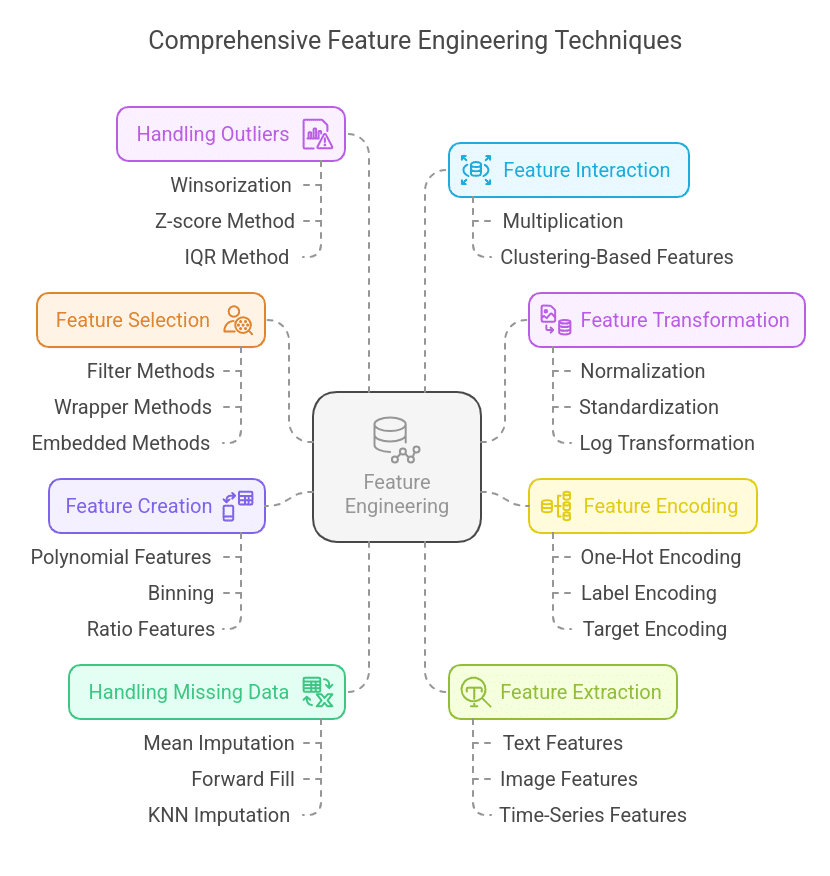
1. Feature Selection
Selecting the most relevant features while eliminating redundant, irrelevant, or highly correlated variables helps improve model efficiency and accuracy.
Techniques:
- Filter Methods: Utilizes statistical techniques like correlation, variance threshold, or mutual information to select important features.
- Wrapper Methods: Employs iterative techniques like Recursive Feature Elimination (RFE) and stepwise selection.
- Embedded Methods: Feature selection is integrated into the algorithm, such as Lasso Regression (L1 regularization) or decision tree-based models.
Example: Removing highly correlated features like “Total Sales” and “Average Monthly Sales” if one can be derived from the other.


