
YOLO (You Only Look Once) is a series of real-time object detection machine-learning algorithms. Object detection, a computer vision task that uses neural networks to localize and classify objects in images, has a wide range of applications, from medical imaging to self-driving cars. Various machine-learning algorithms are utilized for object detection, including convolutional neural networks (CNNs).
CNNs serve as the foundation for any YOLO model, which researchers and engineers utilize for tasks such as object detection and segmentation. YOLO models are open-source and widely used in the field, continuously improving from one version to the next in terms of accuracy, performance, and additional capabilities. This article delves into the entire YOLO family, starting from the original version to the latest, exploring their architecture, use cases, and demonstrations.
About us: Viso Suite is an all-encompassing computer vision platform for enterprises. Within this platform, teams can seamlessly build, deploy, manage, and scale real-time applications for implementation across industries. Viso Suite is use case-agnostic, performing all visual AI-associated tasks, including people counting, defect detection, and safety tracking. To learn more, book a demo with our team.
YOLOv1 The Original
Prior to the introduction of YOLO object detection, researchers utilized convolutional neural network (CNN) based approaches such as R-CNN and Fast R-CNN. These approaches involved a two-step process that predicted bounding boxes and then used regression to classify objects within those boxes. However, this approach was slow and resource-intensive. YOLO models revolutionized object detection when the first YOLO was developed by Joseph Redmon and Ali Farhadi back in 2016, overcoming most issues with traditional object detection algorithms through a new and enhanced architecture.
Architecture
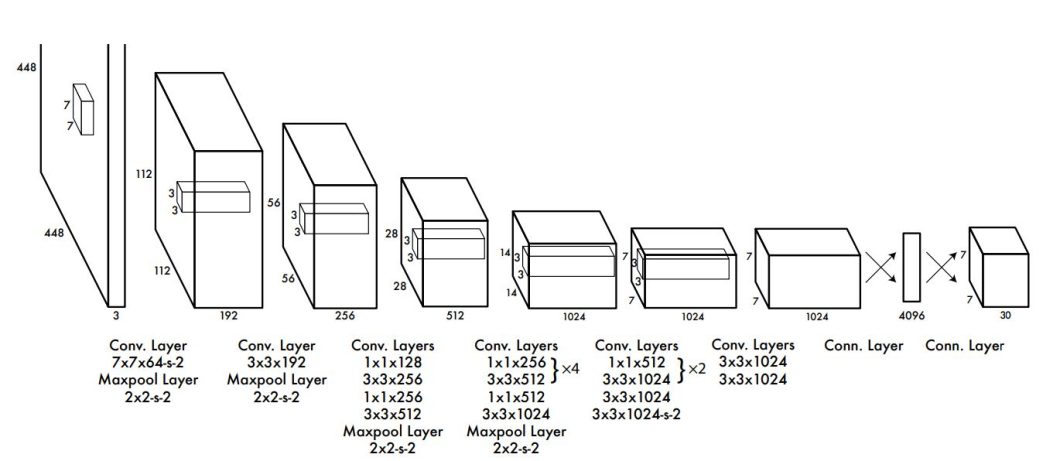
The original YOLO architecture consisted of 24 convolutional layers followed by 2 fully connected layers inspired by the GoogLeNet model for image classification. The YOLOv1 approach was the first of its kind at the time.
The initial convolutional layers of the network extract features from the image while the fully connected layers predict the output probabilities and coordinates. This means that both the bounding boxes and the classification occur in one step, streamlining the operation and achieving real-time efficiency. Additionally, the YOLO architecture utilized optimization techniques such as:
- Leaky ReLU Activation: Prevents the “dying ReLU” problem, where neurons can become stuck in an inactive state during training.
- Dropout Regularization: Applied after the first fully connected layer to prevent overfitting.
- Data Augmentation
How It Works
The essence of YOLO models is treating object detection as a regression problem. The YOLO approach involves applying a single convolutional neural network (CNN) to the entire image. This network divides the image into regions, predicting bounding boxes and probabilities for each region.
These bounding boxes are weighted by the predicted probabilities, which can then be thresholded to display only the high-scoring detections.
 Post navigation
Post navigation


