
When dealing with sequential data in deep learning, Gated Recurrent Units (GRUs) have emerged as an efficient and effective alternative to traditional models like RNNs. In this guide, we’ll explore how GRUs work, their advantages, and their applications in today’s deep learning landscape.
What are GRUs?
GRUs, short for Gated Recurrent Units, are neural networks designed to understand and process sequences such as sentences, time series, or music. Unlike standard networks that treat each input independently, GRUs have the ability to remember previous inputs, which is crucial for capturing context.

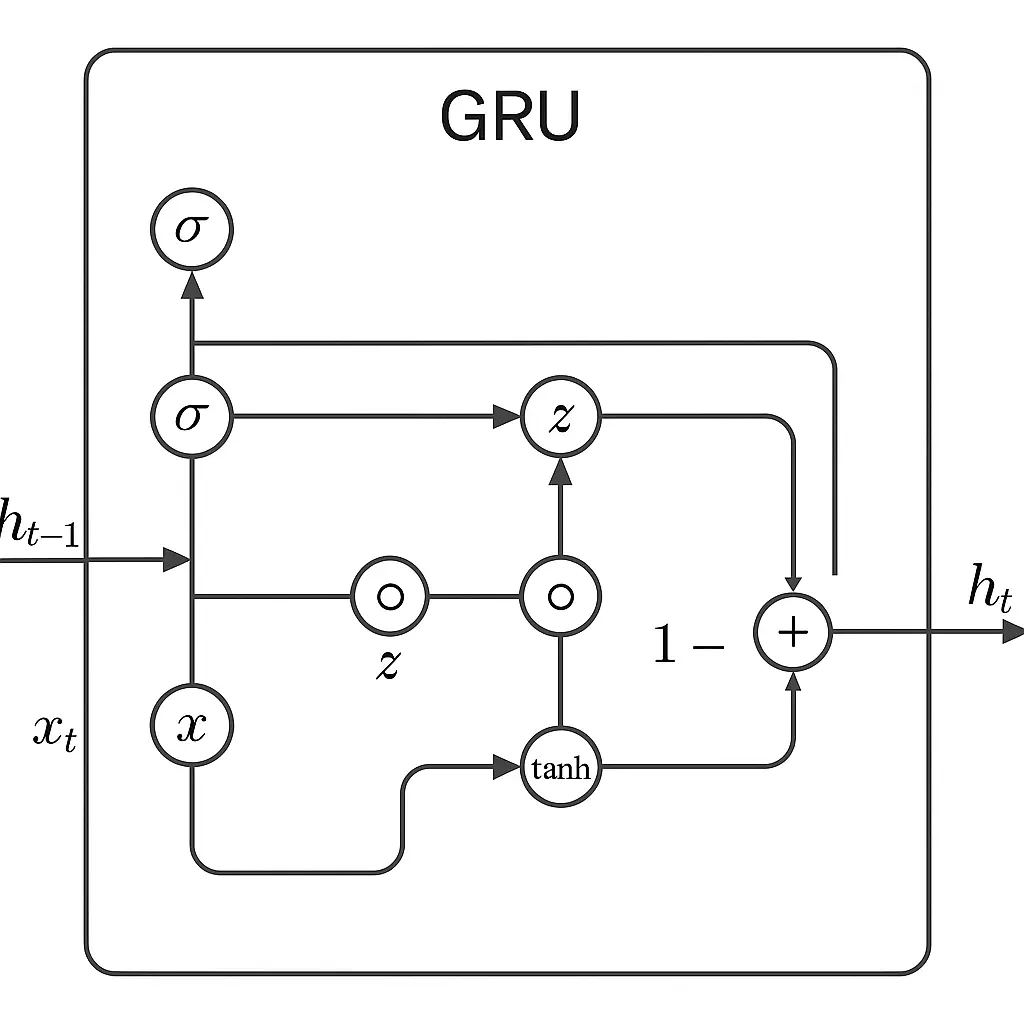
GRUs employ two main “gates” to manage information flow: the update gate controls the retention of past information, while the reset gate helps determine which past information to forget when new input is encountered. This selective memory mechanism enables GRUs to focus on relevant data and disregard noise or irrelevant information.
By blending old and new information intelligently, GRUs can learn patterns across time without being overwhelmed. Compared to LSTMs, GRUs are lighter and faster, making them a practical choice for many deep learning tasks involving sequences.
GRU Equations and Functioning
GRUs utilize specific equations to decide which information to retain and which to discard as they process a sequence. This approach enables GRUs to maintain contextual information over long sequences, allowing them to understand dependencies that span across time.
GRU Diagram
Advantages and Limitations of GRUs
Advantages
- GRUs are known for their simplicity and effectiveness in handling sequential data.
- They excel at retaining important information from earlier sequences, making them ideal for tasks like language processing and time series analysis.
- GRUs require fewer parameters than LSTMs, resulting in faster training and better performance with smaller datasets.
- They converge faster during training, leading to quicker iteration and better accuracy.
Limitations
- GRUs may not perform as well as LSTMs in tasks involving very long or complex sequences.
- They can struggle with retaining information from distant parts of a sequence, impacting performance on tasks with widely spread dependencies.
While GRUs strike a balance between efficiency and performance, they may not be suitable for all scenarios. They are best suited for lightweight, efficient setups but may fall short in tasks requiring extensive memory handling.
Applications of GRUs in Real-World Scenarios
GRUs find applications in various real-world scenarios due to their ability to process sequential data effectively:
- In natural language processing, GRUs are valuable for tasks like machine translation and sentiment analysis.
- They are essential in NLP projects such as chatbots, text classification, and language generation, where understanding and responding to sequences are crucial.
- In time series forecasting, GRUs excel at predicting trends in data like stock prices and weather updates.
- They are utilized in voice recognition to convert spoken words into text, adapting to different speaking styles and accents.
- In healthcare, GRUs help detect anomalies in patient data, aiding in the early identification of health risks.
While GRUs and LSTMs are adept at handling sequential data, they each have strengths based on the task requirements.
When to Choose GRUs Over LSTMs or Other Models
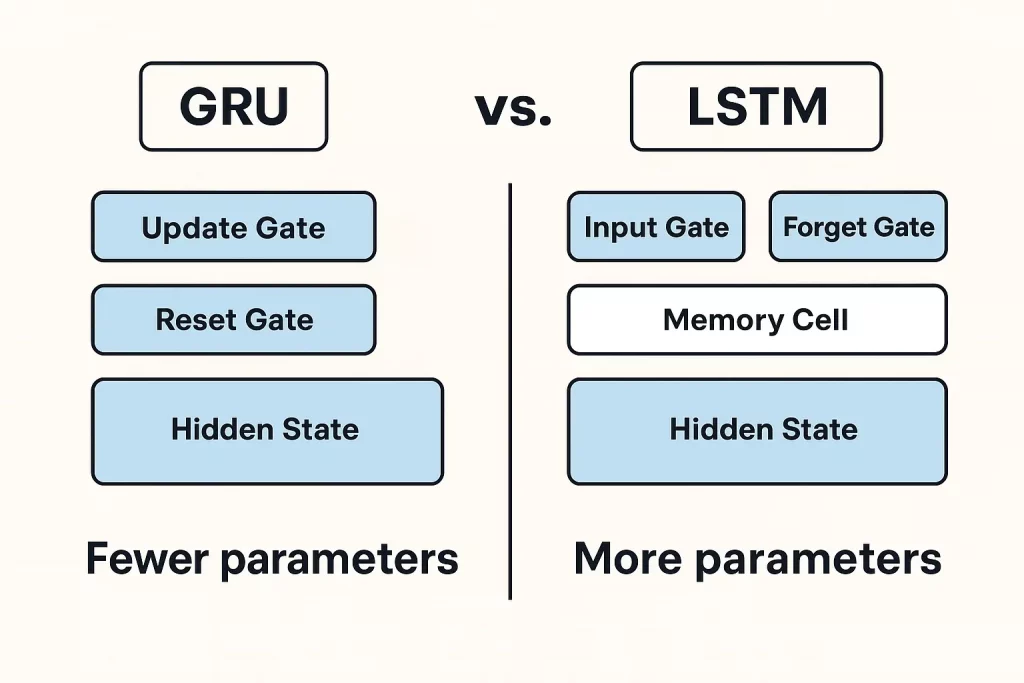
GRUs and LSTMs are recurrent neural networks that differ in complexity and computational efficiency. GRUs, with their simplicity and speed, are ideal for applications where processing speed is critical, such as live analytics and speech recognition.
LSTMs, on the other hand, excel in tasks requiring fine-grained memory control and handling complex dependencies, making them suitable for applications like machine translation and sentiment analysis.
Overall, GRUs are preferred for scenarios with moderate sequence dependencies and speed requirements, while LSTMs are better suited for tasks demanding detailed memory processing and intricate long-term dependencies.
Future of GRU in Deep Learning
GRUs are evolving as lightweight components in modern deep learning pipelines, especially in hybrid models like GRU + Attention. These models are widely used in neural machine translation, time series forecasting, and anomaly detection.
With their compact structure and fast inference capabilities, GRUs are ideal for deployment on edge devices and mobile platforms. They are increasingly used in applications like real-time speech recognition and IoT analytics.
While GRUs may not replace Transformers in large-scale NLP tasks, they remain relevant in low-latency settings that require on-device intelligence and faster processing.
Conclusion
GRUs offer a balance of speed and efficiency, making them valuable for tasks like speech recognition and time series prediction, especially in resource-constrained environments. Understanding the strengths of models like GRUs, LSTMs, and Transformers can help in selecting the right approach for different deep learning tasks.
Continuous exploration of research and experimentation with various models can lead to optimized solutions for real-world data science applications. Programs like Great Learning’s PG Program in AI & Machine Learning provide a structured approach to deep learning and its applications in sequence modeling.


