In today’s data-driven world, the term “cherry-picking” has become increasingly common in the field of data analytics. But what exactly does cherry-picking mean in this context? It refers to the practice of selectively choosing or highlighting data that supports a particular argument or conclusion, while ignoring or disregarding data that contradicts it.
While cherry-picking can be an effective technique for making a point or persuading an audience, it can also be a deceptive practice that distorts the true picture of the data. In this article, we will explore the different ways in which cherry-picking can manifest in data analytics, and the potential consequences of relying on such skewed data. We will also discuss strategies for avoiding cherry-picking and ensuring that your data analysis is objective, accurate, and trustworthy.
What is Cherry Picking in the Context of Data Analytics?
Cherry picking is a type of data analysis technique used to select only the most relevant or desirable data points. It is a process of selecting the “best” pieces of data from a set of data points, based on a predetermined set of criteria. This technique is used to draw conclusions and make decisions based on the data that has been chosen. Cherry picking is an important part of data analytics as it can be used to identify patterns and trends in the data and draw meaningful conclusions.
How is Cherry Picking Used in Data Analytics?
Cherry picking is commonly used in data analytics to identify the most relevant data points that can be used to draw conclusions. It involves selecting only the data points that are most likely to provide meaningful insights, while leaving out any data points that are not as relevant. This type of data analysis can be used to identify trends in the data, as well as to make decisions based on the data.
Steps for Cherry Picking in Data Analytics
The process of cherry picking in data analytics typically involves the following steps:
Step 1: Set Criteria
The first step in cherry picking is to set criteria for selecting the data points. This criteria should be based on the questions you are trying to answer with the data, as well as the type of data you are working with.
Step 2: Select Data Points
Once the criteria have been set, the next step is to select the data points that meet the criteria. This can be done manually by going through each data point and comparing it to the criteria, or it can be done automatically by using a computer program to filter out any data points that do not meet the criteria.
Step 3: Analyze Data Points
Once the data points have been selected, the next step is to analyze the data points. This can be done by looking for patterns and trends in the data, as well as by using statistical analysis to draw meaningful conclusions.
Step 4: Make Decisions
The final step is to make decisions based on the data analysis. This can involve deciding which data points are most relevant, and which should be used to make decisions. It can also involve making decisions about the overall data set, such as which data points should be included or excluded.
Cherry picking is an important technique in data analytics that can be used to select the most relevant data points, as well as to identify patterns and trends in the data. By following the steps outlined above, it is possible to draw meaningful conclusions from the data, as well as to make decisions based on the data.
Frequently Asked Questions
Cherry-picking is a term used to describe the selection of data points that support a particular hypothesis or conclusion, while ignoring data points that do not. It is a common practice in data analytics and can lead to inaccurate conclusions.
What is cherry-picking?
Cherry-picking is a method that is used when analyzing data to select certain data points that support a certain hypothesis or conclusion, while ignoring data points that may contradict the hypothesis or conclusion. This practice is sometimes done intentionally to distort the results of a data analysis. However, it can also be done unintentionally and can lead to inaccurate conclusions.
It is important to be aware of cherry-picking when conducting data analysis, as it can lead to incorrect conclusions. It is also important to note that cherry-picking is not the same as data selection, which is the process of selecting a subset of data points from a larger dataset. Data selection can be used to improve the accuracy of data analysis, but cherry-picking can lead to incorrect conclusions.
What are the consequences of cherry-picking?
Cherry-picking can have serious consequences. It can lead to inaccurate conclusions and decisions based on those conclusions. It can also lead to the misuse of data, as cherry-picking can be used to manipulate data and create a false narrative. This can be particularly damaging in the context of scientific research or decision-making, as inaccurate conclusions can have far-reaching implications.
Additionally, cherry-picking can lead to a lack of trust in data analysis. If people become aware of cherry-picking, they may not trust the conclusions and decisions that are being made based on data analysis. This can lead to a lack of confidence in data analysis and the decisions that are being made based on it.
How can cherry-picking be avoided?
Cherry-picking can be avoided by taking a holistic view of data. Instead of selecting only data points that support a certain hypothesis or conclusion, it is important to consider all of the data points and to look for patterns and trends in the data. This will give a more complete picture of the data and can help to avoid cherry-picking and inaccurate conclusions.
It is also important to be aware of any potential biases that may be present in the data. Bias can lead to cherry-picking, as people may be drawn to certain data points that align with their own preconceived notions. Being aware of potential biases can help to prevent cherry-picking and can lead to more accurate conclusions.
What is the difference between cherry-picking and data selection?
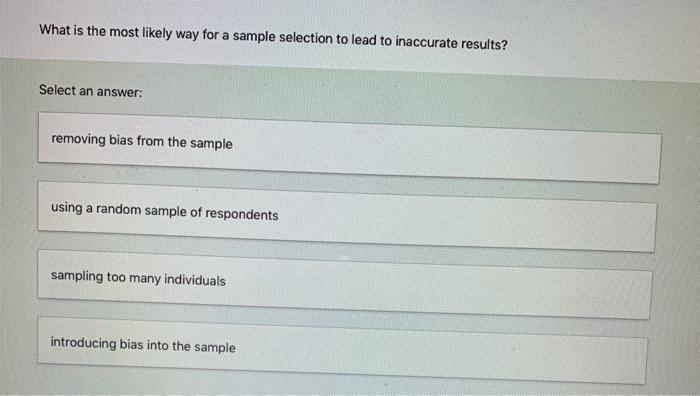
Cherry-picking and data selection are two different processes. Data selection is the process of selecting a subset of data points from a larger dataset. This is often done to improve the accuracy of data analysis. Data selection can be done through various methods, such as random sampling or stratified sampling.
Cherry-picking, on the other hand, is the intentional or unintentional selection of data points that support a certain hypothesis or conclusion, while ignoring data points that may contradict the hypothesis or conclusion. Cherry-picking can lead to inaccurate conclusions, while data selection can help to improve the accuracy of data analysis.
What are some examples of cherry-picking?
Cherry-picking can take many forms. A common example is when a researcher selects only data points that support their hypothesis and ignores data points that may contradict the hypothesis. Another example is when a company selectively uses data points to make a case for a product or service, while ignoring data points that may be unfavorable.
Cherry-picking can also occur when interpreting data. For example, when data is presented in a certain way, such as with certain colors or sizes, the interpretation of the data can be influenced. If a person deliberately or unintentionally selects certain data points to support a certain conclusion, this can be considered cherry-picking.
Data Analytics – Data Fallacies to Avoid: Cherry Picking
In conclusion, cherry-picking refers to the act of selectively choosing data or information to support a particular view or argument while ignoring other facts that may contradict it. It is a common practice in data analytics and research, where analysts may be tempted to only use data that supports their hypothesis or agenda. However, this approach can lead to biased conclusions and inaccurate insights, which can have serious consequences in decision-making processes.
Therefore, it is crucial for data analysts and researchers to be aware of the risks of cherry-picking and strive to avoid it. This can be achieved by using a diverse range of data sources, testing hypotheses rigorously, and considering alternative explanations for findings. Ultimately, by avoiding cherry-picking, data analytics can contribute to more informed decision-making and a better understanding of complex problems.