
Introduction
In the dynamic realm of computer vision, Vision Transformers (ViTs) have emerged as a revolutionary concept. Introduced by Dosovitskiy et al. in the 2020 paper titled “An Image is Worth 16×16 Words: Transformers for Image Recognition,” ViTs have demonstrated significant advancements over traditional convolutional neural network (CNN) approaches. These models offer a novel Transformer architecture that utilizes the attention mechanism for image analysis.
As the demand for advanced computer vision systems continues to grow across various industries, the adoption of Vision Transformers has become a focal point for researchers and practitioners. However, unlocking the full potential of these models requires a deep understanding of their architecture and the development of optimization strategies for efficient deployment.
This article aims to provide an overview of Vision Transformers, delve into their architecture, key components, and the underlying principles that distinguish them. Additionally, optimization strategies to streamline model deployment will be discussed along with a code demo towards the end of the article.
Overview of Transformer Models
ViTs represent a specialized type of neural network primarily used for image classification and object detection. Their superiority over traditional CNNs can be attributed to their foundation on the Transformer architecture. The Transformer neural network architecture, introduced in the 2017 paper “Attention is all you need” by Vaswani et al., operates with an encoder-decoder structure akin to a Recurrent Neural Network (RNN). This architecture processes input sequences without relying on timestamps, allowing all words to be processed simultaneously with concurrent determination of their embeddings.
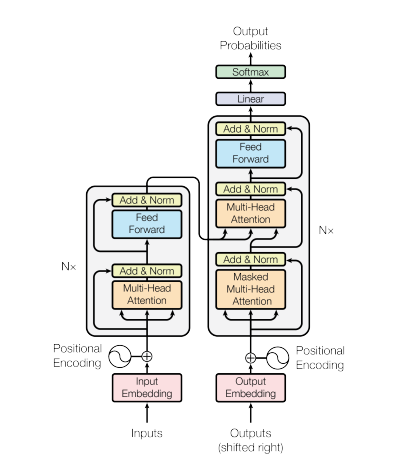
The core of this neural network architecture lies in self-attention, a mechanism that enables the model to weigh different parts of the input sequence while making predictions. Key components of the Transformer architecture include:
- Input-Embeddings: Conversion of input tokens or words into fixed-size vectors for model input, capturing semantic relationships between words.
- Positional Encodings: Addition of positional information to input embeddings to signify the positions of elements in the sequence.
- Encoder-Decoder Structure: Comprising an encoder for input processing and a decoder for output generation in sequence-to-sequence tasks.
- Multi-Head Self-Attention: Allowing the model to focus on different aspects of the input through multiple attention heads.
- Scaled Dot-Product Attention: Computing attention scores through dot products and softmax functions for weighted sum calculations.
- Feedforward Neural Networks: Utilizing activation functions like ReLU post-attention layers for sequential position-wise processing.
- Layer Normalization and Residual Connections: Incorporating layer normalization and residual connections for training stability.
- Encoder and Decoder Stacks: Comprising multiple stacked layers for hierarchical feature extraction.
- Masked Self-Attention in Decoders: Modifying the decoder self-attention mechanism during training to prevent future token dependencies.
- Final Linear and Softmax Layer: Transforming decoder stack output into predicted probabilities for output sequence generation.
Understanding Vision Transformer Architecture
While Convolutional Neural Networks (CNNs) have traditionally dominated image classification tasks, ViTs have consistently outperformed CNNs when trained on sufficiently large datasets. ViTs have marked a significant milestone by successfully training a Transformer encoder on ImageNet, showcasing impressive results compared to established convolutional architectures.
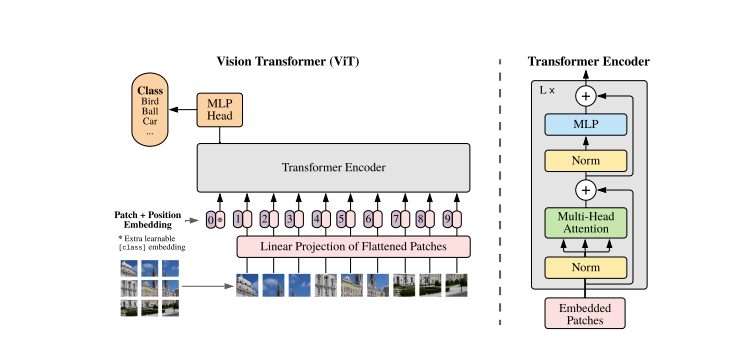
Transformers models handle images and words as sequential inputs to the encoder-decoder. A simplified overview of ViTs includes:
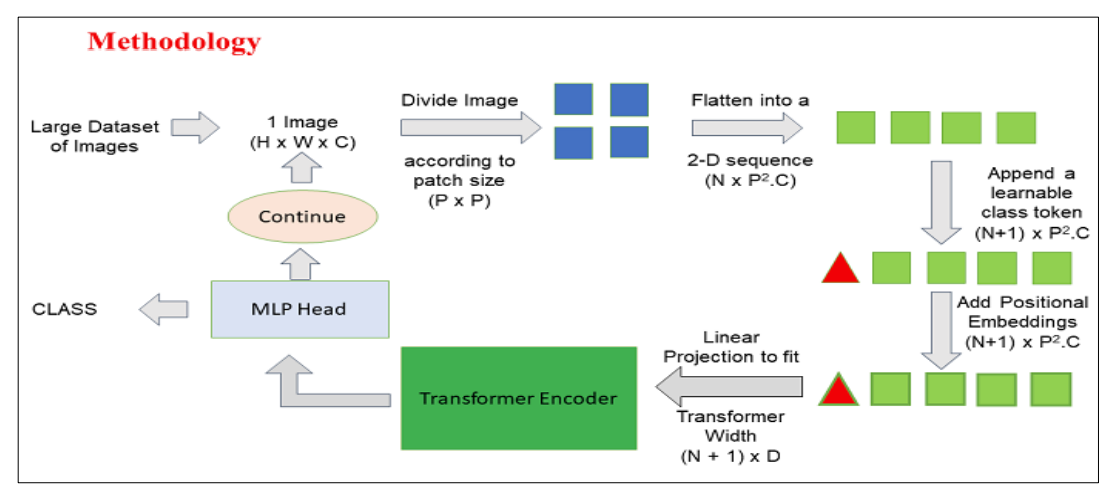
- Patch Extraction: Dividing images into patches fed to the Transformer encoder, where a patch represents a small rectangular section within an image typically measuring 16×16 pixels.

- After dividing the image into non-overlapping patches, each patch is transformed into a feature-representative vector, typically extracted through a CNN trained to identify crucial image characteristics essential for classification.
- Linear Embedding: Transforming extracted patches into linearly embedded flat vectors, serving as input sequences for the Transformer, also known as Linear Projection of Flattened Patches.
- Transformer Encoder: Passing embedded patch vectors through a stack of Transformer encoder layers, each comprising self-attention mechanisms and feedforward neural networks.
- Self-Attention Mechanism: Enabling the model to capture relationships and dependencies between different patches in the image, facilitating learning of long-range interactions and contextual information.
- Positional Encoding: Adding positional encodings to input embeddings to relay patch positions in the original image to the Transformer.
- Multiple Encoder Layers: Leveraging multiple Transformer encoder layers for hierarchical feature extraction from input images.
- Global Average Pooling: Aggregating information from various patches into a fixed-size representation post-Transformer encoder output.
- Classification Head: Directing the pooled representation through a classification head, typically composed of fully connected layers, to yield final outputs for specific computer vision tasks like image classification.
It is highly recommended to refer to the original research paper for a deeper understanding of ViTs architecture.
How to Use
Bring this project to life
Here is a Python demo showcasing how to use the model to classify an image:
# Install the transformers libraries using pip
!pip install -q transformersImport the necessary classes from the Transformer library. ViTFeatureExtractor is used for extracting features from images, and ViTForImageClassification represents a pre-trained ViT model for image classification.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
# Specify the path to the image
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width=700, height=400))

How to use a pre-trained Vision Transformer (ViT) model to predict the class of an input image.
image_array = img.open('/notebooks/football-1419954_640.jpg')
# Loading the ViT Feature Extractor and Model
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
# Extracting Features and Making Predictions
inputs = feature_extractor(images=image_array, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# Model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
# 805
print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: soccer ball
Here is a breakdown of the code:
ViTFeatureExtractor.from_pretrained: Converts the input image into a format suitable for the ViT model.ViTForImageClassification.from_pretrained: Loads a pre-trained ViT model for image classification.feature_extractor: Processes the input image using the ViT feature extractor.model: Pre-trained model processes the input and produces output logits for predictions.- The subsequent steps involve finding the index of the class with the highest logit score and mapping it to its corresponding label.
Originally, the ViT model was pre-trained on the ImageNet-21k dataset, consisting of 14 million images and 21k classes, and fine-tuned on the ImageNet dataset with 1 million images and 1k classes.
Optimization Strategies
ViTs have shown exceptional performance in tasks such as image classification, object detection, and semantic segmentation. However, these architectures necessitate extensive data for training and significant computational resources, leading to heavy model deployment.
Model compression has emerged as a solution to mitigate the resource-intensive nature of models. Various techniques like weight quantization, pruning, and Knowledge Distillation (KD) have been proposed for model compression. KD, in particular, has proven to be an effective method for compressing models, enabling simpler models to achieve comparable performance to the original model.
Knowledge distillation involves transferring knowledge from a complex “teacher” model to a simpler “student” model, allowing the student model to achieve similar task performance. This process typically involves training the student model to mimic the output probabilities or representations of the teacher model, reducing computational resources while maintaining performance.
Several distilled model approaches have proven effective for ViT compression, such as Target aware Transformer, Fine-Grain Manifold Distillation Method, Cross Inductive Bias Distillation (Coadvice), Tiny-ViT, Attention Probe-based Distillation Method, Data-Efficient Image Transformers Distillation via Attention (DeiT), Unified Visual Transformer Compression (UVC), Dear-KD Distillation Method, Cross Architecture Distillation Method, and more.
What is DeiT
A novel technique in the domain of vision transformers, developed by Touvron et al., is Training Data-Efficient Image Transformers Distillation via Attention, known as DeiT. DeiT is a convolution-free transformer exclusively trained on the ImageNet dataset, completing training in less than three days on a single computer. The benchmark model, a vision transformer with 86 million parameters, served as the foundation for DeiT.
DeiT employs a teacher-student strategy utilizing KD, where the student learns from the teacher model through attention mechanisms. The primary concept involves pre-training a large teacher model on a dataset with abundant labeled examples, transferring this knowledge to a smaller student model trained on a target dataset with limited labeled samples.
| ViT | DeiT |
|---|---|
| Required massive dataset not publicly available | Trained only on ImageNet, a 10 times smaller dataset |
| Trained with extensive compute power and longer training time | Trained on a single computer in less than 3 days with a single 8 GPU or 4 GPU machine |
| Required 300 M samples dataset | 30 M samples dataset |
Aside from KD, DeiT incorporates knowledge of Regularization and Data Augmentation. Regularization prevents overfitting and helps the model learn relevant information, while Augmentation artificially expands the dataset by applying transformations to improve data variance. These techniques, along with KD, play significant roles in DeiT, with KD being the primary contributor.
In the original research paper, DeiT introduces a modified KD approach known as Hard Distillation. Here, the teacher network is a state-of-the-art CNN pre-trained on ImageNet, while the student network is a modified transformer version where the CNN output serves as an input to the transformer.
- The hard decision of the teacher network is considered the true label, with the goal associated with hard-label distillation.
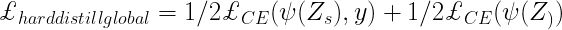
- New distillation tokens interact with class and patch tokens through self-attention layers in subsequent distillation experiments.
- For all distillation experiments, the default teacher is a RegNetY-16GF with 84 million parameters, utilizing the same dataset and data augmentation as DeiT.
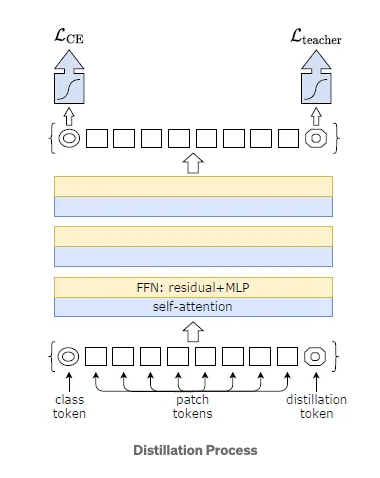
- DeiT Architecture variations:
- DeiT-Ti: Tiny model with 5M parameters
- DeiT-S: Small model with 22M parameters
- DeiT-B: Large model with 86M parameters
- DeiT-b 384: Fine-tuned model for a larger resolution of 384×384
- DeiT: Utilizes the distillation process
The efficacy of hard distillation can be assessed in the image below, with accuracy reaching nearly 83%, a level unattainable through soft distillation. Additionally, distillation tokens yield slightly better results.
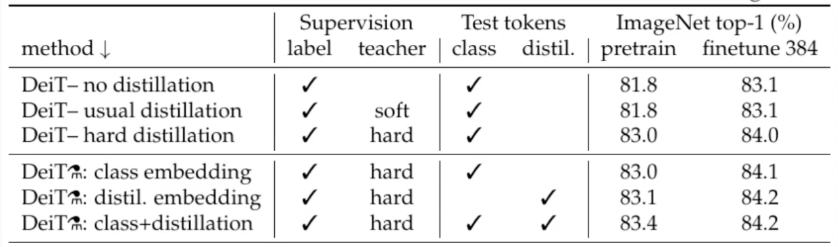
- Training DeiT-B for 300 epochs typically requires 37 hours on 2 nodes or 53 hours on a single 8-GPU node.
A Code Demo and In-Depth Understanding for Efficient Deployment
Bring this project to life
DeiT showcases the successful application of Transformers in computer vision tasks, even with limited data availability and resources.
Classifying Images with DeiT
For detailed instructions on image classification using DeiT, refer to the README.md of the DeiT repository. Alternatively, for a quick test, start by installing the necessary packages:
!pip install torch torchvision timm pandas requestsNext, execute the following script:
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# Should be 1.8.0
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_


