
Interpreting and analyzing sequential data is essential in today’s AI world, whether it’s predicting the next word in a sentence or identifying trends in financial markets.
Traditional neural networks struggle with learning long-term patterns, which led to the introduction of LSTM (Long Short-Term Memory) – a specific recurrent neural network that revolutionized how machines handle time-dependent data.
This article delves into how LSTM functions, its architecture, the decoding algorithm it uses, and its applications across various industries.
Understanding LSTM
LSTM is a type of Recurrent Neural Network (RNN) designed to overcome the limitations of standard RNNs in tracking long-term dependencies, thanks to its memory cells and gate mechanisms.
Introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997, LSTM has been particularly effective in tasks like speech recognition, language modeling, and time series forecasting, where understanding the context over time is crucial.
LSTM Architecture: Components and Design
Overview of LSTM as an Advanced RNN with Added Complexity
LSTM, an extension of RNNs, features a more intricate architecture to help the network remember, forget, and output information over longer sequences. This complexity makes LSTM superior in tasks requiring deep context understanding.
Core Components
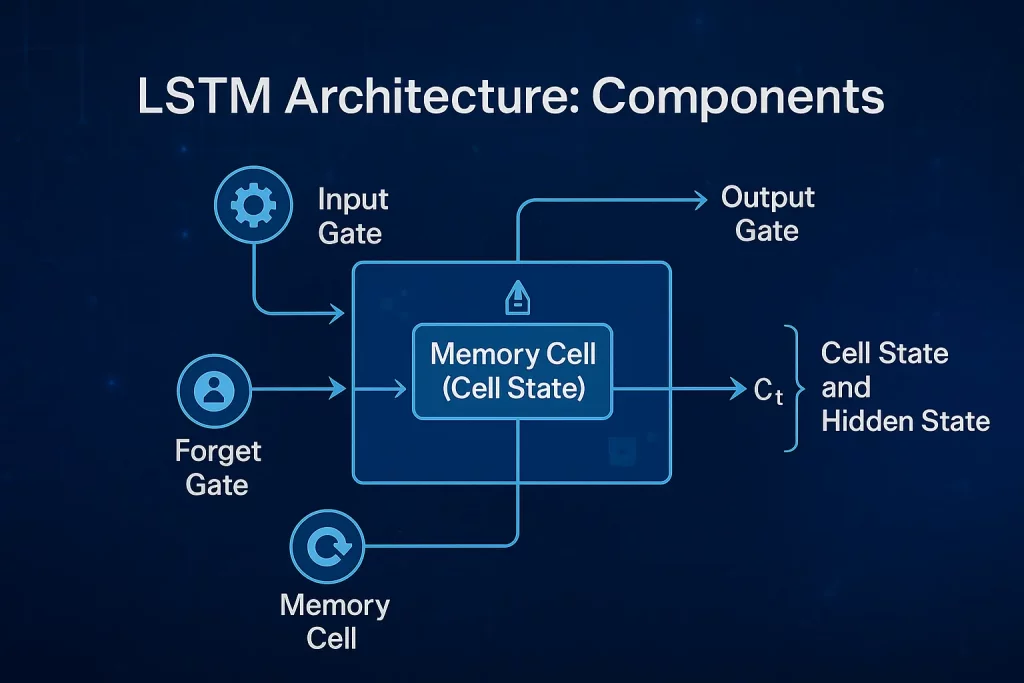
- Memory Cell (Cell State): The core of the LSTM unit, responsible for carrying information across time steps with minimal alterations to capture long-term dependencies.
- Input Gate: Controls the entry of new information into the memory cell, storing only relevant data through activation and candidate vector generation.
- Forget Gate: Determines what should be discarded from the memory cell to avoid memory overload.
- Output Gate: Decides which information from the current cell state influences the next step in the sequence.
Cell State and Hidden State:
- Cell State (Ct): Carries long-term memory modified by input and forget gates.
- Hidden State (ht): Represents the output value of the LSTM unit at a specific time step, transferred to the next unit and often used in final predictions.
How do These Components Work Together?
- Forget: The forget gate determines what information to discard from the cell state based on the previous hidden state and current input.
- Input: The input gate and candidate values decide on new information to add to the cell state.
- Update: The cell state is updated by merging old and new information through the forget and input gates.
- Output: The output gate uses the updated cell state to produce the next hidden state, influencing the next step in the sequence.
This gated system enables LSTMs to maintain a balanced memory, retaining crucial patterns while discarding unnecessary noise traditional RNNs struggle with.
LSTM Algorithm: How It Works

- Input at Time Step : LSTM receives current input and previous hidden state and cell state for each time step.
- Forget Gate (ft): Determines what to discard from the previous cell state using a sigmoid function.
- Input Gate (it): Controls new information added to the cell state through a sigmoid and tanh function.
- Cell State Update (Ct): Combines previous and new information to update the cell state.
- Output Gate (ot): Determines which part of the cell state is output as the hidden state.
Mathematical Equations for Gates and State Updates in LSTM
- Forget Gate (ft): Decides what to discard from the previous cell state through a sigmoid function.
- Input Gate (it): Controls new information added to the cell state using a sigmoid and tanh function.
- Cell State Update (Ct): Updates the cell state by combining previous and new information.
- Output Gate (ot): Determines the output from the cell state as the hidden state.
Comparison: LSTM vs Vanilla RNN Cell Operations
| Feature | Vanilla RNN | LSTM |
| Memory Mechanism | Single hidden state vector | Dual memory: Cell state + Hidden state |
| Gate Mechanism | No explicit gates | Multiple gates (forget, input, output) |
| Handling Long-Term Dependencies | Struggles with vanishing gradients | Effectively captures long-term dependencies |
| Vanishing Gradient Problem | Significant issue | Mitigated by cell state and gates |
| Update Process | Simple update formula | Complex gate interactions for updates |
| Memory Management | No specific memory retention | Explicit memory control |
| Output Calculation | Direct output | Output controlled by gate decision |
Training LSTM Networks
1. Data Preparation for Sequential Tasks
Data preprocessing is critical for LSTM performance:
- Sequence Padding: Ensure uniform sequence length by padding shorter sequences.
- Normalization: Scale numerical features for stability.
- Time Windowing: Create input-output pairs for temporal pattern learning.
- Train-Test Split: Divide data into training, validation, and test sets while maintaining temporal order.
2. Model Configuration: Layers, Hyperparameters, and Initialization
- Layer Design: Start with an LSTM layer and end with a Dense output layer.
- Hyperparameters:
- Learning Rate: Choose a suitable value.
- Batch Size: Opt for a standard batch size.
- Number of Units: Determine units per LSTM layer.
- Dropout Rate: Apply dropout to prevent overfitting.
- Weight Initialization: Use Glorot or He initialization for faster convergence.
3. Training Process
- Backpropagation Through Time (BPTT): Calculate gradients by unrolling LSTM over time for sequential learning.
- Gradient Clipping: Clip gradients to avoid exploding gradients.
- Optimization Algorithms: Use Adam or RMSprop for effective training.
Applications of LSTM in Deep Learning

1. Time Series Forecasting
Application: LSTM networks excel in forecasting tasks like stock prices, weather conditions, and sales data due to their ability to capture long-term dependencies.
2. Natural Language Processing (NLP)
Application: LSTMs are widely used in NLP tasks such as machine translation and sentiment analysis, leveraging their contextual understanding capabilities.
3. Speech Recognition
Application: LSTMs play a key role in speech-to-text applications by accurately capturing temporal dependencies in spoken language.
4. Anomaly Detection in Sequential Data
Application: LSTMs are effective in detecting anomalies in data streams, aiding in tasks like fraud detection and sensor malfunction detection.
5. Video Processing and Action Recognition
Application: LSTMs are utilized in video analysis for tasks like action recognition by processing sequences of frames to classify human actions.
Conclusion
LSTM networks are pivotal in solving complex problems involving sequential data across various domains. To enhance your skills in the AI field, consider exploring the Post Graduate Program in Artificial Intelligence and Machine Learning offered by Great Learning, designed in collaboration with the McCombs School of Business at The University of Texas at Austin.
This comprehensive program covers topics like NLP, Generative AI, and Deep Learning through hands-on projects, mentorship from industry experts, and dual certification, preparing you for success in AI and ML roles.


